इस कार्य के भाग के रूप में, निम्नलिखित प्रश्नों पर विचार किया जाएगा:
- ओलाप क्यूब्स क्या हैं?
- उपाय, आयाम, पदानुक्रम क्या हैं?
- OLAP क्यूब पर किस प्रकार के ऑपरेशन किए जा सकते हैं?
OLAP का मुख्य अभिधारणा डेटा प्रस्तुति में बहुआयामी है। OLAP शब्दावली में, क्यूब या हाइपरक्यूब की अवधारणा का उपयोग बहुआयामी असतत डेटा स्थान का वर्णन करने के लिए किया जाता है।
घनक्षेत्रएक बहुआयामी डेटा संरचना है जिससे एक विश्लेषक उपयोगकर्ता जानकारी को क्वेरी कर सकता है। क्यूब्स तथ्यों और आयामों से बनाए जाते हैं।
आंकड़े- यह कंपनी में वस्तुओं और घटनाओं के बारे में डेटा है जो विश्लेषण के अधीन होगा। एक ही प्रकार के तथ्य उपायों का निर्माण करते हैं। घन सेल में एक माप एक प्रकार का मान है।
मापनडेटा तत्व हैं जिन पर तथ्यों का विश्लेषण किया जाता है। ऐसे तत्वों का संग्रह आयाम की विशेषता बनाता है (उदाहरण के लिए, सप्ताह के दिन आयाम "समय" की विशेषता बना सकते हैं)। वाणिज्यिक उद्यमों के व्यापार विश्लेषण के कार्यों में, "समय", "बिक्री", "उत्पाद", "ग्राहक", "कर्मचारी", "भौगोलिक स्थान" जैसी श्रेणियां अक्सर माप के रूप में कार्य करती हैं। आयाम अक्सर पदानुक्रमित संरचनाएं होती हैं जो तार्किक श्रेणियां होती हैं जिनके विरुद्ध उपयोगकर्ता वास्तविक डेटा का विश्लेषण कर सकता है। प्रत्येक पदानुक्रम में एक या अधिक स्तर हो सकते हैं। तो "भौगोलिक स्थान" आयाम के पदानुक्रम में स्तर शामिल हो सकते हैं: "देश - क्षेत्र - शहर"। समय के पदानुक्रम में, उदाहरण के लिए, स्तरों के निम्नलिखित अनुक्रम को प्रतिष्ठित किया जा सकता है: एक आयाम में कई पदानुक्रम हो सकते हैं (इस मामले में, एक आयाम के प्रत्येक पदानुक्रम में आयाम तालिका की समान कुंजी विशेषता होनी चाहिए)।
घन में एक या अधिक तथ्य तालिकाओं से वास्तविक डेटा हो सकता है, और अक्सर इसमें कई आयाम होते हैं। किसी विशेष घन में आमतौर पर विश्लेषण का एक विशेष दिशात्मक विषय होता है।
चित्र 1 क्षेत्र द्वारा एक निश्चित कंपनी द्वारा पेट्रोलियम उत्पादों की बिक्री का विश्लेषण करने के लिए डिज़ाइन किए गए घन का एक उदाहरण दिखाता है। इस घन के तीन आयाम (समय, उत्पाद और क्षेत्र) और एक माप (मौद्रिक संदर्भ में व्यक्त बिक्री मूल्य) है। माप मान घन के संबंधित कक्षों (सेल) में संग्रहीत होते हैं। प्रत्येक सेल को विशिष्ट रूप से प्रत्येक आयाम के सदस्यों के एक समूह द्वारा पहचाना जाता है, जिसे टपल कहा जाता है। उदाहरण के लिए, क्यूब के निचले बाएं कोने में स्थित सेल (इसमें मूल्य $98399 है) टपल [जुलाई 2005, सुदूर पूर्व, डीजल] द्वारा दिया गया है। यहां $98399 का मूल्य जुलाई 2005 में सुदूर पूर्व में डीजल की बिक्री (मौद्रिक संदर्भ में) की मात्रा को दर्शाता है।
यह भी ध्यान दें कि कुछ कक्षों में कोई मान नहीं होता है: ये कक्ष खाली होते हैं क्योंकि तथ्य तालिका में उनके लिए डेटा नहीं होता है।
चावल। 1.विभिन्न क्षेत्रों में पेट्रोलियम उत्पादों की बिक्री के बारे में जानकारी वाला घन
ऐसे क्यूब्स बनाने का अंतिम लक्ष्य प्रश्नों के प्रसंस्करण समय को कम करना है जो वास्तविक डेटा से आवश्यक जानकारी निकालते हैं। इस कार्य को पूरा करने के लिए, क्यूब्स में आमतौर पर प्रीकंप्यूटेड सारांश डेटा होता है जिसे कहा जाता है एकत्रित(एकत्रीकरण)। वे। क्यूब एक डेटा स्पेस को वास्तविक से बड़ा कवर करता है - इसमें तार्किक, परिकलित बिंदु होते हैं। कुल कार्य आपको वास्तविक मूल्यों के आधार पर तार्किक स्थान में बिंदु मानों की गणना करने की अनुमति देते हैं। सबसे सरल एकत्रीकरण कार्य SUM, MAX, MIN, COUNT हैं। इसलिए, उदाहरण के लिए, उदाहरण में दिखाए गए घन के लिए MAX फ़ंक्शन का उपयोग करके, आप यह पहचान सकते हैं कि सुदूर पूर्व में डीजल की बिक्री में चरम कब हुआ, आदि।
बहुआयामी घनों की एक अन्य विशिष्ट विशेषता मूल बिंदु को निर्धारित करने में कठिनाई है। उदाहरण के लिए, आप उत्पाद या क्षेत्र आयाम के लिए बिंदु 0 कैसे सेट करते हैं? इस समस्या का समाधान एक विशेष विशेषता का परिचय देना है जो आयाम के सभी तत्वों को जोड़ती है। इस विशेषता (स्वचालित रूप से उत्पन्न) में केवल एक तत्व होता है - सभी ("सभी")। सरल एकत्रीकरण कार्यों जैसे कि रकम के लिए, सभी तत्व दिए गए आयाम के वास्तविक स्थान में सभी तत्वों के मूल्यों के योग के बराबर हैं।
बहुआयामी डेटा मॉडल में एक महत्वपूर्ण अवधारणा उप-स्थान या उप-घन है। एक उपघन घन के अंदर कुछ बहुआयामी आकृति के रूप में पूर्ण घन स्थान का एक हिस्सा है। चूँकि एक घन का बहुआयामी स्थान असतत और घिरा हुआ है, उपघन भी असतत और घिरा हुआ है।
OLAP क्यूब्स पर संचालन
एक OLAP क्यूब पर निम्नलिखित ऑपरेशन किए जा सकते हैं:
- काटना;
- रोटेशन;
- समेकन;
- विवरण।

चावल। 2.ओलाप क्यूब स्लाइस
ROTATION(चित्र 3) - रिपोर्ट में या प्रदर्शित पृष्ठ पर प्रस्तुत मापों के स्थान को बदलने का कार्य। उदाहरण के लिए, एक रोटेशन ऑपरेशन में तालिका की पंक्तियों और स्तंभों की अदला-बदली शामिल हो सकती है। इसके अलावा, डेटा क्यूब को घुमाने से गैर-टेबल आयामों को प्रदर्शित पृष्ठ पर मौजूद आयामों के स्थान पर ले जाया जाता है, और इसके विपरीत।
व्याख्या: यह व्याख्यान OLAP डेटा वेयरहाउस के लिए डेटा क्यूब डिजाइन करने की मूल बातें शामिल करता है। उदाहरण दिखाता है कि CASE टूल का उपयोग करके डेटा क्यूब कैसे बनाया जाता है।
व्याख्यान का उद्देश्य
इस व्याख्यान की सामग्री का अध्ययन करने के बाद, आप जानेंगे:
- डेटा क्यूब क्या होता है OLAP डेटा वेयरहाउस ;
- के लिए डेटा क्यूब कैसे डिज़ाइन करें OLAP डेटा वेयरहाउस ;
- डेटा क्यूब डायमेंशन क्या है;
- तथ्य डेटा क्यूब से कैसे संबंधित है;
- आयाम विशेषताएँ क्या हैं;
- एक पदानुक्रम क्या है;
- डेटा क्यूब मीट्रिक क्या है;
और जानें:
- निर्माण बहुआयामी चार्ट ;
- डिजाइन सरल बहुआयामी चार्ट.
परिचय
OLAP तकनीक अकेली नहीं है सॉफ़्टवेयर, नहीं प्रोग्रामिंग भाषा. यदि आप OLAP को उसकी सभी अभिव्यक्तियों में शामिल करने का प्रयास करते हैं, तो यह अवधारणाओं, सिद्धांतों और आवश्यकताओं का एक समूह है जो सॉफ़्टवेयर उत्पादों के अंतर्गत आता है जो विश्लेषकों के लिए डेटा तक पहुँच को आसान बनाता है।
विश्लेषक कॉर्पोरेट जानकारी के मुख्य उपभोक्ता हैं। एक विश्लेषक का काम बड़े डेटा सेट में पैटर्न खोजना है। इसलिए, विश्लेषक इस तथ्य पर ध्यान नहीं देंगे कि एक निश्चित दिन पर खरीदार इवानोव को बॉलपॉइंट पेन का एक बैच बेचा गया था - उन्हें सैकड़ों और हजारों समान घटनाओं के बारे में जानकारी चाहिए। डेटा वेयरहाउस में एकल तथ्य रुचि के हो सकते हैं, उदाहरण के लिए, एक एकाउंटेंट या बिक्री विभाग के प्रमुख, जिनकी क्षमता एक विशिष्ट अनुबंध का समर्थन करने के लिए है। एक विश्लेषक के लिए एक रिकॉर्ड पर्याप्त नहीं है - उदाहरण के लिए, उसे एक महीने, तिमाही या वर्ष के लिए सभी बिक्री बिंदु अनुबंधों के बारे में जानकारी की आवश्यकता हो सकती है। एनालिटिक्स को खरीदार के टीआईएन या उसके फोन नंबर में दिलचस्पी नहीं हो सकती है - वह विशिष्ट संख्यात्मक डेटा के साथ काम करता है, जो कि उसकी पेशेवर गतिविधि का सार है।
केंद्रीकरण और सुविधाजनक संरचना एक विश्लेषक की जरूरत से बहुत दूर हैं। उसे देखने, जानकारी की कल्पना करने के लिए एक उपकरण की आवश्यकता होती है। हालांकि, एकल डेटा वेयरहाउस के आधार पर निर्मित पारंपरिक रिपोर्टें, हालांकि, एक निश्चित लचीलेपन से वंचित हैं। डेटा के वांछित दृश्य को प्राप्त करने के लिए उन्हें "मुड़", "विस्तृत" या "ढह" नहीं किया जा सकता है। विश्लेषक जितना अधिक "कट" और "कट" डेटा का पता लगा सकता है, उसके पास उतने ही अधिक विचार हैं, जो सत्यापन के लिए अधिक से अधिक "कट" की आवश्यकता होती है। डेटा अन्वेषण के लिए एक उपकरण के रूप में, विश्लेषक OLAP है।
हालाँकि OLAP डेटा वेयरहाउस की एक आवश्यक विशेषता नहीं है, लेकिन इस डेटा वेयरहाउस में संचित जानकारी का विश्लेषण करने के लिए इसका तेजी से उपयोग किया जा रहा है।
परिचालन डेटा को विभिन्न स्रोतों से एकत्र किया जाता है, साफ किया जाता है, एकीकृत किया जाता है और डेटा वेयरहाउस में जोड़ा जाता है। साथ ही, वे पहले से ही विभिन्न रिपोर्टिंग टूल का उपयोग करके विश्लेषण के लिए उपलब्ध हैं। फिर डेटा (पूरे या आंशिक रूप से) OLAP विश्लेषण के लिए तैयार किया जाता है। उन्हें एक विशेष OLAP डेटाबेस में लोड किया जा सकता है या रिलेशनल डेटा वेयरहाउस में छोड़ा जा सकता है। OLAP का उपयोग करने का सबसे महत्वपूर्ण तत्व मेटाडेटा है, यानी संरचना, स्थान और के बारे में जानकारी डेटा परिवर्तन. उनके लिए धन्यवाद, विभिन्न भंडारण घटकों की प्रभावी बातचीत सुनिश्चित की जाती है।
इस प्रकार, OLAP को डेटा वेयरहाउस में संचित डेटा के बहुआयामी विश्लेषण के लिए उपकरणों के एक सेट के रूप में परिभाषित किया जा सकता है. सैद्धांतिक रूप से, OLAP उपकरण सीधे परिचालन डेटा या पर लागू किए जा सकते हैं सटीक प्रतियां. हालांकि, विश्लेषण के अधीन डेटा का जोखिम है जो इस विश्लेषण के लिए उपयुक्त नहीं है।
क्लाइंट और सर्वर पर ओलाप
OLAP के केंद्र में बहुआयामी डेटा विश्लेषण है। इसे विभिन्न उपकरणों का उपयोग करके उत्पादित किया जा सकता है, जिन्हें सशर्त रूप से क्लाइंट और सर्वर OLAP टूल में विभाजित किया जा सकता है।
क्लाइंट-साइड OLAP टूल ऐसे एप्लिकेशन हैं जो कुल डेटा (रकम, औसत, अधिकतम या न्यूनतम) की गणना और प्रदर्शित करते हैं, और कुल डेटा को OLAP टूल के एड्रेस स्पेस के भीतर ही कैश किया जाता है।
यदि स्रोत डेटा डेस्कटॉप DBMS में समाहित है, तो समग्र डेटा की गणना OLAP टूल द्वारा ही की जाती है। यदि स्रोत डेटा का स्रोत एक सर्वर DBMS है, तो कई क्लाइंट OLAP टूल सर्वर को GROUP BY क्लॉज वाली SQL क्वेरी भेजते हैं, और परिणामस्वरूप सर्वर पर गणना किए गए कुल डेटा प्राप्त करते हैं।
एक नियम के रूप में, OLAP कार्यक्षमता सांख्यिकीय डेटा प्रोसेसिंग टूल (इस वर्ग के उत्पादों से लेकर रूसी बाजारस्टेट सॉफ्ट और एसपीएसएस उत्पादों का व्यापक रूप से उपयोग किया जाता है) और कुछ स्प्रेडशीट्स में। विशेष रूप से, Microsoft Excel 2000. इस उत्पाद के साथ, आप फ़ाइल के रूप में एक छोटा स्थानीय बहुआयामी OLAP क्यूब बना सकते हैं और सहेज सकते हैं और इसके दो-या तीन-आयामी अनुभाग प्रदर्शित कर सकते हैं।
अनेक विकास उपकरणकक्षाओं या घटकों के पुस्तकालय होते हैं जो आपको ऐसे अनुप्रयोग बनाने की अनुमति देते हैं जो सरलतम OLAP कार्यक्षमता को लागू करते हैं (जैसे बोरलैंड डेल्फी और बोरलैंड सी ++ बिल्डर में डिसीजन क्यूब घटक)। इसके अलावा भी कई कंपनियां ऑफर करती हैं को नियंत्रित करता हैएक्टिवएक्स और अन्य पुस्तकालय जो समान कार्यक्षमता को लागू करते हैं।
ध्यान दें कि क्लाइंट OLAP टूल का उपयोग, एक नियम के रूप में, आयामों की एक छोटी संख्या के साथ किया जाता है (आमतौर पर छह से अधिक की सिफारिश नहीं की जाती है) और इन मापदंडों के लिए मूल्यों की एक छोटी विविधता - आखिरकार, प्राप्त समग्र डेटा में फिट होना चाहिए इस तरह के एक उपकरण का पता स्थान, और संख्या माप में वृद्धि के साथ उनकी संख्या तेजी से बढ़ती है। इसलिए, यहां तक कि सबसे आदिम क्लाइंट OLAP टूल, एक नियम के रूप में, आपको इसमें एक बहुआयामी क्यूब बनाने के लिए आवश्यक रैम की मात्रा की प्रारंभिक गणना करने की अनुमति देता है।
कई (लेकिन सभी नहीं) क्लाइंट-साइड OLAP टूल आपको समग्र डेटा कैश की सामग्री को फ़ाइल के रूप में संग्रहीत करने की अनुमति देते हैं, जो बदले में उन्हें पुनर्गणना करने से रोकता है। ध्यान दें कि इस अवसर का उपयोग अक्सर अन्य संगठनों को या प्रकाशन के लिए उन्हें स्थानांतरित करने के लिए समग्र डेटा को अलग करने के लिए किया जाता है। इस तरह के विमुख कुल डेटा का एक विशिष्ट उदाहरण विभिन्न क्षेत्रों में और विभिन्न आयु समूहों में घटना के आँकड़े हैं, जो कि है खुली जानकारीस्वास्थ्य मंत्रालय द्वारा प्रकाशित विभिन्न देशऔर विश्व स्वास्थ्य संगठन। साथ ही, मूल डेटा ही, जो बीमारियों के विशिष्ट मामलों के बारे में जानकारी है, चिकित्सा संस्थानों का गोपनीय डेटा है और किसी भी मामले में बीमा कंपनियों के हाथों में नहीं पड़ना चाहिए, सार्वजनिक होने की तो बात ही छोड़ दें।
एक फ़ाइल में समग्र डेटा के कैश को संग्रहीत करने के विचार को सर्वर-साइड OLAP टूल में और विकसित किया गया है, जिसमें कुल डेटा का भंडारण और संशोधन, साथ ही साथ भंडारण का रखरखाव, इसके द्वारा किया जाता है। एक अलग एप्लिकेशन या प्रक्रिया जिसे OLAP सर्वर कहा जाता है। क्लाइंट एप्लिकेशन ऐसे बहुआयामी भंडारण का अनुरोध कर सकते हैं और प्रतिक्रिया में कुछ डेटा प्राप्त कर सकते हैं। कुछ क्लाइंट एप्लिकेशन ऐसे स्टोर भी बना सकते हैं या बदले हुए स्रोत डेटा के अनुसार उन्हें अपडेट कर सकते हैं।
क्लाइंट OLAP टूल की तुलना में सर्वर OLAP टूल का उपयोग करने के फायदे डेस्कटॉप वाले की तुलना में सर्वर DBMS का उपयोग करने के लाभों के समान हैं: सर्वर टूल का उपयोग करने के मामले में, कुल डेटा की गणना और संग्रहण सर्वर और क्लाइंट एप्लिकेशन पर होता है उन्हें केवल प्रश्नों के परिणाम प्राप्त होते हैं, जो आम तौर पर नेटवर्क ट्रैफ़िक को कम करने की अनुमति देता है, समय सीमाक्लाइंट एप्लिकेशन द्वारा उपभोग किए गए अनुरोध और संसाधन आवश्यकताएं। ध्यान दें कि एंटरप्राइज़-स्केल विश्लेषण और डेटा प्रोसेसिंग, एक नियम के रूप में, सर्वर OLAP टूल पर सटीक रूप से आधारित होते हैं, उदाहरण के लिए, जैसे कि Oracle Express Server, Microsoft SQL Server 2000 विश्लेषण सेवाएँ, Hyperion Essbase, क्रिस्टल निर्णयों के उत्पाद, व्यावसायिक वस्तुएँ, Cognos , एसएएस संस्थान। चूंकि सर्वर DBMS के सभी प्रमुख निर्माता कुछ सर्वर OLAP टूल का उत्पादन करते हैं (या अन्य कंपनियों से लाइसेंस प्राप्त करते हैं), उनकी पसंद काफी विस्तृत है, और लगभग सभी मामलों में आप डेटाबेस सर्वर के रूप में उसी निर्माता से OLAP सर्वर खरीद सकते हैं।
ध्यान दें कि कई क्लाइंट OLAP टूल (विशेष रूप से, Microsoft Excel 2003, सीगेट एनालिसिस, आदि) आपको सर्वर OLAP स्टोरेज एक्सेस करने की अनुमति देते हैं, इस मामले में ऐसे क्लाइंट एप्लिकेशन के रूप में काम करते हैं जो इस तरह की क्वेरी करते हैं। इसके अलावा, ऐसे कई उत्पाद हैं जो विभिन्न निर्माताओं के OLAP टूल के लिए क्लाइंट एप्लिकेशन हैं।
बहुआयामी डेटा भंडारण के तकनीकी पहलू
बहुआयामी डेटा वेयरहाउस में विवरण की अलग-अलग डिग्री का कुल डेटा होता है, उदाहरण के लिए, दिन, महीने, वर्ष, उत्पाद श्रेणी आदि के अनुसार बिक्री की मात्रा। समग्र डेटा को संग्रहीत करने का उद्देश्य कम करना है समय सीमाअनुरोध, क्योंकि ज्यादातर मामलों में, विश्लेषण और पूर्वानुमान के लिए, यह विस्तृत नहीं है, लेकिन सारांश डेटा जो रुचि का है। इसलिए, एक बहुआयामी डेटाबेस बनाते समय, कुछ समग्र डेटा की हमेशा गणना और भंडारण किया जाता है।
ध्यान दें कि सभी समग्र डेटा को सहेजना हमेशा उचित नहीं होता है। तथ्य यह है कि नए आयाम जोड़ते समय, घन बनाने वाले डेटा की मात्रा तेजी से बढ़ती है (कभी-कभी वे डेटा की मात्रा के "विस्फोटक विकास" के बारे में कहते हैं)। अधिक विशेष रूप से, समग्र डेटा वृद्धि की मात्रा घन में आयामों की संख्या और उन आयामों के पदानुक्रम के विभिन्न स्तरों पर आयामों के सदस्यों पर निर्भर करती है। "विस्फोटक विकास" की समस्या को हल करने के लिए, विभिन्न योजनाओं का उपयोग किया जाता है, जो क्वेरी निष्पादन की स्वीकार्य गति प्राप्त करने के लिए, सभी संभावित कुल डेटा से दूर की गणना करते समय अनुमति देते हैं।
स्रोत और समग्र डेटा दोनों को संबंधपरक या बहुआयामी संरचनाओं में संग्रहीत किया जा सकता है। इसलिए, वर्तमान में डेटा स्टोर करने के तीन तरीके हैं।
- मोलाप(बहुआयामी OLAP) - स्रोत और कुल डेटा को एक बहुआयामी डेटाबेस में संग्रहीत किया जाता है। बहुआयामी संरचनाओं में डेटा संग्रहीत करने से आप डेटा को बहुआयामी सरणी के रूप में हेरफेर कर सकते हैं, ताकि किसी भी आयाम के लिए कुल मूल्यों की गणना की गति समान हो। हालाँकि, इस मामले में, बहुआयामी डेटाबेस निरर्थक है, क्योंकि बहुआयामी डेटा में पूरी तरह से मूल संबंधपरक डेटा होता है।
- रोलप(रिलेशनल OLAP) - मूल डेटा उसी रिलेशनल डेटाबेस में रहता है जहाँ वह मूल रूप से रहता था। एग्रीगेट डेटा को उसी डेटाबेस में उनके स्टोरेज के लिए विशेष रूप से बनाई गई सर्विस टेबल में रखा जाता है।
- होलाप(हाइब्रिड OLAP) - मूल डेटा उसी रिलेशनल डेटाबेस में रहता है जहाँ वह मूल रूप से रहता था, जबकि समग्र डेटा एक बहुआयामी डेटाबेस में संग्रहीत होता है।
कुछ OLAP उपकरण केवल संबंधपरक संरचनाओं में डेटा संग्रहण का समर्थन करते हैं, कुछ - केवल बहुआयामी वाले में। हालाँकि, अधिकांश आधुनिक OLAP सर्वर उपकरण तीनों डेटा संग्रहण विधियों का समर्थन करते हैं। भंडारण विधि का चुनाव स्रोत डेटा की मात्रा और संरचना, क्वेरी निष्पादन की गति की आवश्यकताओं और OLAP क्यूब्स को अद्यतन करने की आवृत्ति पर निर्भर करता है।
हम यह भी ध्यान देते हैं कि अधिकांश आधुनिक OLAP उपकरण "खाली" मूल्यों को संग्रहीत नहीं करते हैं ("खाली" मूल्य का एक उदाहरण मौसमी सामानों की बिक्री का अभाव होगा)।
बुनियादी OLAP अवधारणाएँ
एफएएमएसआई परीक्षण
जटिल बहुआयामी डेटा विश्लेषण की तकनीक को OLAP (ऑन-लाइन विश्लेषणात्मक प्रसंस्करण) कहा जाता है। OLAP डेटा वेयरहाउस संगठन का एक प्रमुख घटक है। OLAP की अवधारणा को 1993 में प्रसिद्ध डेटाबेस शोधकर्ता और रिलेशनल डेटा मॉडल के लेखक एडगर कॉड द्वारा वर्णित किया गया था। 1995 में, Codd, तथाकथित द्वारा निर्धारित आवश्यकताओं के आधार पर एफएएसएमआई परीक्षण(साझा बहुआयामी जानकारी का तेज़ विश्लेषण) - बहुआयामी विश्लेषण के लिए अनुप्रयोगों के लिए निम्नलिखित आवश्यकताओं सहित साझा बहुआयामी जानकारी का तेज़ विश्लेषण:
- तेज़(फास्ट) - कम विस्तृत विश्लेषण की कीमत पर भी उपयोगकर्ता को उचित समय (आमतौर पर 5 एस से अधिक नहीं) में विश्लेषण परिणाम प्रदान करना;
- विश्लेषण(विश्लेषण) - किसी दिए गए एप्लिकेशन के लिए विशिष्ट तार्किक और सांख्यिकीय विश्लेषण करने की क्षमता और इसे अंतिम उपयोगकर्ता के लिए सुलभ रूप में सहेजना;
- साझा(साझा) - उचित लॉकिंग तंत्र और अधिकृत एक्सेस टूल्स के समर्थन के साथ डेटा तक बहु-उपयोगकर्ता पहुंच;
- बहुआयामी(बहुआयामी) - डेटा का बहुआयामी वैचारिक प्रतिनिधित्व, जिसमें पदानुक्रम और कई पदानुक्रमों के लिए पूर्ण समर्थन शामिल है (यह एक प्रमुख OLAP आवश्यकता है);
- जानकारी(सूचना) - एप्लिकेशन को इसकी मात्रा और भंडारण स्थान की परवाह किए बिना किसी भी आवश्यक जानकारी तक पहुंचने में सक्षम होना चाहिए।
यह ध्यान दिया जाना चाहिए कि OLAP कार्यक्षमता लागू की जा सकती है विभिन्न तरीके, कार्यालय अनुप्रयोगों में सबसे सरल डेटा विश्लेषण उपकरण से शुरू होता है और सर्वर उत्पादों पर आधारित वितरित विश्लेषणात्मक प्रणालियों के साथ समाप्त होता है।
सूचना का बहुआयामी प्रतिनिधित्व
क्यूबा
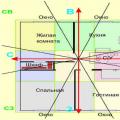
OLAP व्यावसायिक जानकारी तक पहुँचने, देखने और विश्लेषण करने का एक सुविधाजनक, उच्च गति वाला साधन प्रदान करता है। उपयोगकर्ता एक प्राकृतिक, सहज ज्ञान युक्त हो जाता है डेटा मॉडल, उन्हें बहुआयामी क्यूब्स (क्यूब्स) के रूप में व्यवस्थित करना. बहुआयामी समन्वय प्रणाली की कुल्हाड़ियाँ विश्लेषण की गई व्यावसायिक प्रक्रिया की मुख्य विशेषताएँ हैं। उदाहरण के लिए, बिक्री के लिए यह एक उत्पाद, क्षेत्र, खरीदार का प्रकार हो सकता है। समय का उपयोग मापों में से एक के रूप में किया जाता है। माप (आयाम) के कुल्हाड़ियों के चौराहों पर ऐसे डेटा होते हैं जो मात्रात्मक रूप से प्रक्रिया की विशेषता रखते हैं - उपाय (उपाय)। ये टुकड़ों में या मौद्रिक शब्दों में, स्टॉक बैलेंस, लागत आदि में बिक्री की मात्रा हो सकती है। जानकारी का विश्लेषण करने वाला उपयोगकर्ता घन को विभिन्न दिशाओं में "कट" कर सकता है, सारांश प्राप्त कर सकता है (उदाहरण के लिए, वर्षों से) या, इसके विपरीत, विस्तृत (साप्ताहिक) जानकारी और विश्लेषण की प्रक्रिया में उसके दिमाग में आने वाली अन्य जोड़-तोड़ करता है।
अंजीर में दिखाए गए त्रि-आयामी घन में उपायों के रूप में। 26.1, बिक्री की मात्रा का उपयोग किया जाता है, और समय, उत्पाद और स्टोर को माप के रूप में उपयोग किया जाता है। मापन पर दिखाया गया है निश्चित स्तरसमूहीकरण: माल को श्रेणियों, दुकानों - देशों द्वारा, और लेन-देन के समय डेटा - महीनों के आधार पर समूहीकृत किया जाता है। थोड़ी देर बाद हम समूहीकरण स्तरों (पदानुक्रम) को अधिक विस्तार से देखेंगे।
चावल। 26.1।
क्यूब को "काटना"
यहां तक कि एक त्रि-आयामी घन को कंप्यूटर स्क्रीन पर प्रदर्शित करना मुश्किल होता है ताकि ब्याज के उपायों के मूल्यों को देखा जा सके। हम तीन से अधिक आयामों वाले घनों के बारे में क्या कह सकते हैं। एक घन में संग्रहीत डेटा को देखने के लिए, एक नियम के रूप में, सामान्य द्वि-आयामी, यानी सारणीबद्ध प्रतिनिधित्व का उपयोग किया जाता है, जिसमें जटिल पदानुक्रमित पंक्ति और स्तंभ शीर्षलेख होते हैं।
एक घन का द्वि-आयामी प्रतिनिधित्व एक या अधिक अक्षों (आयामों) के साथ इसे "काट" कर प्राप्त किया जा सकता है: हम दो को छोड़कर सभी आयामों के मूल्यों को ठीक करते हैं, और हमें एक नियमित द्वि-आयामी प्राप्त होता है मेज़। तालिका का क्षैतिज अक्ष (कॉलम हेडर) एक आयाम का प्रतिनिधित्व करता है, ऊर्ध्वाधर अक्ष (पंक्ति शीर्षलेख) दूसरे आयाम का प्रतिनिधित्व करता है, और तालिका कक्ष माप मानों का प्रतिनिधित्व करते हैं। इस मामले में, उपायों के सेट को वास्तव में आयामों में से एक माना जाता है: हम या तो प्रदर्शन के लिए एक माप का चयन करते हैं (और फिर हम पंक्तियों और स्तंभों के शीर्षकों में दो आयाम रख सकते हैं), या हम कई उपाय दिखाते हैं (और फिर एक तालिका के कुल्हाड़ियों के उपायों के नाम पर कब्जा कर लिया जाएगा, और अन्य - एक "अनकटा" आयाम के मान)।
(स्तर)। उदाहरण के लिए, प्रस्तुत किए गए लेबल सभी OLAP टूल द्वारा समर्थित नहीं हैं। उदाहरण के लिए, Microsoft विश्लेषण सेवा 2000 में दोनों प्रकार के पदानुक्रम का समर्थन किया जाता है, जबकि Microsoft OLAP सेवा 7.0 में केवल संतुलित पदानुक्रम का समर्थन किया जाता है। अलग-अलग OLAP टूल में पदानुक्रम स्तरों की संख्या, और एक स्तर के सदस्यों की अधिकतम स्वीकार्य संख्या, और स्वयं आयामों की अधिकतम संभव संख्या हो सकती है।ओएलएपी एप्लीकेशन आर्किटेक्चर
OLAP के बारे में जो कुछ ऊपर कहा गया है, वास्तव में, डेटा की बहुआयामी प्रस्तुति को संदर्भित करता है। जिस तरह से डेटा संग्रहीत किया जाता है, मोटे तौर पर बोलना, अंतिम उपयोगकर्ता या क्लाइंट द्वारा उपयोग किए जाने वाले टूल के डेवलपर्स से संबंधित नहीं है।
OLAP अनुप्रयोगों में बहुआयामी को तीन स्तरों में विभाजित किया जा सकता है।
- बहुआयामी डेटा प्रतिनिधित्व - अंत-उपयोगकर्ता उपकरण जो बहुआयामी दृश्य और डेटा हेरफेर प्रदान करते हैं; बहुआयामी प्रतिनिधित्व परत डेटा की भौतिक संरचना से सार करती है और डेटा को बहुआयामी मानती है।
- बहुआयामी प्रसंस्करण - बहुआयामी प्रश्नों को तैयार करने के लिए एक उपकरण (भाषा) (पारंपरिक संबंधपरक SQL भाषा यहाँ अनुपयुक्त है) और एक प्रोसेसर जो इस तरह की क्वेरी को संसाधित और निष्पादित कर सकता है।
- बहुआयामी भंडारण - डेटा के भौतिक संगठन का मतलब है जो बहुआयामी प्रश्नों का कुशल निष्पादन प्रदान करता है।
सभी OLAP टूल में पहले दो स्तर अनिवार्य हैं। तीसरा स्तर, हालांकि व्यापक रूप से उपयोग किया जाता है, इसकी आवश्यकता नहीं है, क्योंकि बहुआयामी प्रतिनिधित्व के लिए डेटा को साधारण संबंधपरक संरचनाओं से भी पुनर्प्राप्त किया जा सकता है; इस मामले में बहुआयामी क्वेरी प्रोसेसर बहुआयामी प्रश्नों को एसक्यूएल प्रश्नों में अनुवादित करता है जो एक रिलेशनल डीबीएमएस द्वारा निष्पादित होते हैं।
विशिष्ट OLAP उत्पाद आमतौर पर या तो एक बहुआयामी डेटा प्रस्तुति उपकरण (OLAP क्लाइंट - उदाहरण के लिए, Microsoft से Excel 2000 में Pivot Tables या Knosys से ProClarity) या एक बहुआयामी बैक-एंड DBMS (OLAP सर्वर - उदाहरण के लिए, Oracle Express Server या Microsoft OLAP) होते हैं। सेवाएं)।
बहुआयामी प्रसंस्करण परत आमतौर पर OLAP क्लाइंट और/या OLAP सर्वर में निर्मित होती है, लेकिन इसे इसके शुद्धतम रूप में अलग किया जा सकता है, जैसे कि Microsoft की पिवट टेबल सर्विस घटक।
/ क्यूबिस्ट तरीके से। बड़ी कंपनियों के प्रबंधन अभ्यास में OLAP क्यूब्स का उपयोग
के साथ संपर्क में
सहपाठियों
कॉन्स्टेंटिन टोकमाचेव, सिस्टम वास्तुकार
क्यूबिस्ट तरीके से।
बड़ी कंपनियों के प्रबंधन अभ्यास में OLAP क्यूब्स का उपयोग
शायद वह समय पहले ही बीत चुका है जब निगम के कंप्यूटिंग संसाधनों को सूचना और लेखा रिपोर्ट के पंजीकरण पर ही खर्च किया गया था। उसी समय, कार्यालयों में, बैठकों और सत्रों में प्रबंधकीय निर्णय "आँख से" लिए जाते थे। शायद रूस में कॉर्पोरेट कंप्यूटिंग सिस्टम पर लौटने का समय उनके मुख्य संसाधन - कंप्यूटर में पंजीकृत डेटा के आधार पर नियंत्रण समस्याओं को हल करना है।
व्यापार खुफिया के लाभों के बारे में
कॉर्पोरेट प्रबंधन पाश में, "कच्चे" डेटा और प्रबंधित वस्तु को प्रभावित करने के "लीवर" के बीच, "प्रदर्शन संकेतक" - KPI हैं। वे एक "डैशबोर्ड" बनाते हैं, जो नियंत्रित वस्तु के विभिन्न उप-प्रणालियों की स्थिति को दर्शाता है। कंपनी को जानकारीपूर्ण प्रदर्शन संकेतकों से लैस करना और उनकी गणना और प्राप्त मूल्यों को नियंत्रित करना एक व्यापार विश्लेषक का काम है। एक निगम के विश्लेषणात्मक कार्य को व्यवस्थित करने में महत्वपूर्ण सहायता स्वचालित विश्लेषण सेवाओं, जैसे एमएस द्वारा प्रदान की जा सकती है एस क्यू एल सर्वरएनालिसिस सर्विसेज (एसएसएएस) और इसका मुख्य डिस्पोज़िटिव एक ओलाप क्यूब है।
यहां एक और नोट बनाया जाना है। उदाहरण के लिए, अमेरिकी परंपरा में, OLAP क्यूब्स के साथ काम करने पर केंद्रित एक विशेषता को बीआई (बिजनेस इंटेलिजेंस) कहा जाता है। कोई भ्रम नहीं होना चाहिए कि अमेरिकी बीआई रूसी "व्यापार विश्लेषक" से मेल खाता है। कोई अपराध नहीं, लेकिन अक्सर हमारे व्यापार विश्लेषक एक "अंडर-अकाउंटेंट" और "अंडर-प्रोग्रामर" होते हैं, अस्पष्ट ज्ञान और एक छोटे वेतन वाले विशेषज्ञ, जिनके पास वास्तव में अपना कोई उपकरण और कार्यप्रणाली नहीं होती है।
एक बीआई विशेषज्ञ, वास्तव में, एक अनुप्रयुक्त गणितज्ञ, एक उच्च श्रेणी का विशेषज्ञ होता है जो आधुनिक गणितीय विधियों को फर्मों के साथ सेवा में रखता है (जिसे संचालन अनुसंधान - संचालन अनुसंधान के तरीके कहा जाता था)। बीआई विशेष "सिस्टम एनालिस्ट" के अनुरूप है जो यूएसएसआर में हुआ करता था, जिसे मॉस्को स्टेट यूनिवर्सिटी के वीएमके के संकाय द्वारा निर्मित किया गया था। एम.वी. लोमोनोसोव। OLAP घन और विश्लेषण सेवाएं एक रूसी व्यापार विश्लेषक के कार्यस्थल के लिए एक आशाजनक आधार बन सकती हैं, शायद अमेरिकी BI के प्रति उनकी योग्यता में कुछ सुधार के बाद।
में हाल तकएक और हानिकारक प्रवृत्ति सामने आई है। विशेषज्ञता के लिए धन्यवाद, निगम के कर्मचारियों की विभिन्न श्रेणियों के बीच आपसी समझ खो गई है। लेखाकार, प्रबंधक और प्रोग्रामर, I.A की कथा में "हंस, कैंसर और पाईक" की तरह। क्रायलोव, निगम को अलग-अलग दिशाओं में खींच रहा है।
लेखाकार रिपोर्ट करने में व्यस्त है, इसकी राशियाँ, अर्थ और गतिशीलता दोनों में, सीधे कंपनी की व्यावसायिक प्रक्रिया से संबंधित नहीं हैं।
प्रबंधक व्यवसाय प्रक्रिया के अपने खंड के साथ व्यस्त है, लेकिन वैश्विक रूप से, कंपनी के स्तर पर, अपने कार्यों के परिणामों और संभावनाओं का आकलन करने में सक्षम नहीं है।
अंत में, प्रोग्रामर, जो एक बार (शिक्षा के लिए धन्यवाद) विज्ञान के क्षेत्र से व्यवसाय के क्षेत्र में उन्नत तकनीकी विचारों का संवाहक था, एक लेखाकार और प्रबंधक की कल्पनाओं का एक निष्क्रिय निष्पादक बन गया है, इसलिए यह अब नहीं है असामान्य जब एकाउंटेंट और आम तौर पर हर कोई आलसी नहीं होता है। बिन बुलाए, अनपढ़, लेकिन अपेक्षाकृत उच्च भुगतान वाला 1C प्रोग्रामर रूसी निगमों का एक वास्तविक संकट है। (लगभग एक घरेलू फुटबॉल खिलाड़ी की तरह।) मैं तथाकथित "अर्थशास्त्रियों और वकीलों" के बारे में बात नहीं कर रहा हूं, उनके बारे में सब कुछ लंबे समय से कहा गया है।
तो, एक उच्च तकनीक SSAS तंत्र से लैस एक व्यावसायिक विश्लेषक की स्थिति, जो प्रोग्रामिंग और लेखांकन की मूल बातें जानता है, व्यवसाय प्रक्रिया के विश्लेषण और पूर्वानुमान के संबंध में कंपनी के काम को समेकित करने में सक्षम है।
OLAP क्यूब्स के लाभ
ओलाप क्यूब है आधुनिक सुविधाकॉर्पोरेट कंप्यूटर सिस्टम के डेटाबेस का विश्लेषण, जो कंपनी के उत्पादन प्रक्रिया की विशेषता वाले संकेतकों के आवश्यक सेट के साथ पदानुक्रम के सभी स्तरों के कर्मचारियों को प्रदान करने की अनुमति देता है। बात केवल यह नहीं है कि एमडीएक्स (मल्टीडायमेंशनल एक्सप्रेशन) क्यूब के लिए उपयोगकर्ता के अनुकूल इंटरफेस और लचीली क्वेरी भाषा आपको आवश्यक विश्लेषणात्मक संकेतकों को तैयार करने और गणना करने की अनुमति देती है, बल्कि उल्लेखनीय गति और आसानी से यह ओएलएपी क्यूब करता है। इसके अलावा, ये गति और आसानी, कुछ सीमाओं के भीतर, गणना की जटिलता और डेटाबेस की मात्रा पर निर्भर नहीं करते हैं।
ओलाप की कुछ समझ
क्यूब "पिवट टेबल" एमएस एक्सेल दे सकता है। इन वस्तुओं में समान तर्क और समान इंटरफेस हैं। लेकिन, जैसा कि लेख से देखा जाएगा, OLAP की कार्यक्षमता अतुलनीय रूप से समृद्ध है, और प्रदर्शन अतुलनीय रूप से उच्च है, ताकि "पिवट टेबल" एक स्थानीय डेस्कटॉप उत्पाद बना रहे, जबकि OLAP एक उद्यम स्तर का उत्पाद है।
विश्लेषणात्मक समस्याओं को हल करने के लिए OLAP क्यूब इतना उपयुक्त क्यों है? OLAP क्यूब को इस तरह से डिज़ाइन किया गया है कि सभी संभावित वर्गों में सभी संकेतक पूर्व-गणना किए गए हैं (पूरे या आंशिक रूप से), और उपयोगकर्ता को केवल आवश्यक संकेतकों (माप उपायों) और वर्गों (आयाम आयामों) को "बाहर निकालना" है ) माउस के साथ, और प्रोग्राम प्लेट्स को फिर से बनाता है।
सभी वर्गों में सभी संभावित विश्लेषण एक विशाल क्षेत्र बनाते हैं, या बल्कि, एक क्षेत्र नहीं, बल्कि एक बहुआयामी OLAP क्यूब। कोई भी उपयोगकर्ता (प्रबंधक, व्यवसाय विश्लेषक, प्रबंधक) एनालिटिक्स सेवा के लिए जो भी अनुरोध करता है, प्रतिक्रिया की गति दो चीजों के कारण होती है: सबसे पहले, आवश्यक एनालिटिक्स को आसानी से तैयार किया जा सकता है (या तो सूची से नाम से चुना गया है, या एक सूत्र द्वारा दिया गया है) एमडीएक्स भाषा में), और दूसरी बात, एक नियम के रूप में, इसकी गणना पहले ही की जा चुकी है।
एनालिटिक्स का सूत्रीकरण तीन संस्करणों में संभव है: यह या तो एक डेटाबेस फ़ील्ड है (अधिक सटीक रूप से, एक वेयरहाउस फ़ील्ड), या क्यूब डिज़ाइन स्तर पर परिभाषित गणना फ़ील्ड, या क्यूब के साथ अंतःक्रियात्मक रूप से काम करते समय एक एमडीएक्स भाषा अभिव्यक्ति।
इसका अर्थ है OLAP क्यूब्स की कई आकर्षक विशेषताएं एक साथ। वास्तव में, उपयोगकर्ता और डेटा के बीच की बाधा गायब हो जाती है। एक एप्लिकेशन प्रोग्रामर के रूप में एक बाधा, जिसे सबसे पहले समस्या को समझाने की जरूरत है (एक कार्य निर्धारित करें)। दूसरे, आपको तब तक इंतजार करना होगा जब तक कि एप्लिकेशन प्रोग्रामर एल्गोरिदम नहीं बनाता है, प्रोग्राम लिखता है और डिबग करता है, फिर इसे संशोधित किया जा सकता है। यदि कई कर्मचारी हैं और उनकी आवश्यकताएं विविध और परिवर्तनशील हैं, तो लागू प्रोग्रामरों की एक पूरी टीम की जरूरत है। इस अर्थ में, विश्लेषणात्मक कार्य के संदर्भ में एक OLAP क्यूब (और एक योग्य व्यवसाय विश्लेषक) एप्लिकेशन प्रोग्रामर की एक पूरी टीम की जगह लेता है, ठीक उसी तरह जैसे एक बेकहो चालक के साथ एक शक्तिशाली उत्खननकर्ता जब खाई खोदता है तो फावड़े से अतिथि श्रमिकों की एक पूरी ब्रिगेड को बदल देता है!
इस मामले में, प्राप्त विश्लेषणात्मक डेटा का एक और बहुत महत्वपूर्ण गुण हासिल किया जाता है। चूँकि OLAP क्यूब पूरी कंपनी के लिए एक है, अर्थात चूंकि यह सभी के लिए विश्लेषकों के साथ एक ही क्षेत्र है, डेटा में एक कष्टप्रद असंगति को बाहर रखा गया है। जब एक प्रबंधक को व्यक्तिपरक कारक को खत्म करने के लिए कई स्वतंत्र कर्मचारियों को एक ही कार्य निर्धारित करना पड़ता है, लेकिन वे अभी भी अलग-अलग उत्तर लाते हैं, जो हर किसी को किसी न किसी तरह समझाने का उपक्रम करता है, आदि। OLAP क्यूब कॉर्पोरेट पदानुक्रम के विभिन्न स्तरों पर विश्लेषणात्मक डेटा की एकरूपता सुनिश्चित करता है, अर्थात। यदि प्रबंधक उसके लिए रुचि के एक निश्चित संकेतक का विवरण देना चाहता है, तो वह निश्चित रूप से निचले स्तर के डेटा पर आ जाएगा, जिसके साथ उसका अधीनस्थ काम करता है, और यह केवल वह डेटा होगा जिसके आधार पर उच्च-स्तरीय संकेतक की गणना की जाती है , और कुछ अन्य डेटा नहीं, किसी अन्य तरीके से प्राप्त किया गया, किसी अन्य समय पर, आदि। यानी पूरी कंपनी एक ही एनालिटिक्स देखती है, लेकिन समेकन के विभिन्न स्तरों पर।
आइए एक उदाहरण लेते हैं। मान लीजिए कि एक प्रबंधक प्राप्य खातों को नियंत्रित करता है। जब तक अतिदेय प्राप्तियों का KPI हरा है, तब तक सब कुछ सामान्य है, किसी प्रबंधन कार्रवाई की आवश्यकता नहीं है। यदि रंग बदलकर पीला या लाल हो गया है, तो कुछ गलत है: हम बिक्री विभाग द्वारा KPI को काट देते हैं और तुरंत "लाल रंग" में विभाजन देखते हैं। प्रबंधकों - और विक्रेता, जिनके ग्राहक भुगतान में देर कर रहे हैं, पर अगला खंड परिभाषित किया गया है। (आगे, देरी की राशि को खरीदारों द्वारा, शर्तों आदि से विभाजित किया जा सकता है।) निगम के प्रमुख किसी भी स्तर पर उल्लंघनकर्ताओं को सीधे संबोधित कर सकते हैं। लेकिन सामान्य तौर पर, समान KPI (उनके पदानुक्रम स्तरों पर) दोनों विभाग प्रमुखों और बिक्री प्रबंधकों द्वारा देखा जाता है। इसलिए, स्थिति को ठीक करने के लिए, उन्हें "कार्पेट पर कॉल" की प्रतीक्षा करने की भी आवश्यकता नहीं है ... बेशक, KPI के लिए आवश्यक रूप से अपराध की राशि होना आवश्यक नहीं है - यह एक भारित औसत हो सकता है चूक अवधि या, सामान्य तौर पर, प्राप्य टर्नओवर की दर।
ध्यान दें कि MDX भाषा की जटिलता और लचीलापन, तेज (कभी-कभी तात्कालिक) परिणामों के साथ, जटिल नियंत्रण कार्यों को हल करना (विकास और डिबगिंग के चरणों को ध्यान में रखते हुए) संभव बनाता है, जो अन्य परिस्थितियों में, प्रस्तुत नहीं किया गया हो सकता है एप्लाइड प्रोग्रामर्स के लिए जटिलता और फॉर्मूलेशन में शुरुआती अनिश्चितता के कारण बिल्कुल भी नहीं। (अनुप्रयोग प्रोग्रामर्स के लिए लंबे समय की समय-सीमा खराब समझी गई फॉर्मूलेशन और लंबी प्रोग्राम संशोधनों के कारण विश्लेषणात्मक समस्याओं को हल करने के लिए होती है, जब परिस्थितियों में परिवर्तन अक्सर व्यवहार में होता है।)
आइए इस तथ्य पर भी ध्यान दें कि कंपनी का प्रत्येक कर्मचारी OLAP विश्लेषक सामान्य क्षेत्र से ठीक उसी फसल को इकट्ठा कर सकता है जिसकी उसे काम करने की आवश्यकता है, और "पट्टी" से संतुष्ट न हों जिसे उसने सांप्रदायिक "मानक रिपोर्ट" में काटा है। ”।
क्लाइंट-सर्वर मोड में OLAP क्यूब के साथ काम करने के लिए एक बहु-उपयोगकर्ता इंटरफ़ेस प्रत्येक कर्मचारी को, दूसरों से स्वतंत्र रूप से, अपने स्वयं के (यहां तक कि कुछ कौशल के साथ अपने स्वयं के उत्पादन) एनालिटिक्स ब्लॉक (रिपोर्ट) की अनुमति देता है, जो एक बार परिभाषित हो जाते हैं, स्वचालित रूप से अद्यतन - दूसरे शब्दों में, वे हमेशा अद्यतित स्थिति में रहते हैं।
यही है, OLAP क्यूब आपको विश्लेषणात्मक कार्य करने की अनुमति देता है (जो वास्तव में न केवल नोट विश्लेषकों द्वारा किया जाता है, बल्कि, वास्तव में, कंपनी के लगभग सभी कर्मचारियों द्वारा, यहां तक कि तर्कशास्त्री और प्रबंधक जो संतुलन और शिपमेंट को नियंत्रित करते हैं) अधिक चयनात्मक, " चेहरे से सामान्य अभिव्यक्ति में नहीं ”, जो काम में सुधार और उत्पादकता बढ़ाने के लिए परिस्थितियाँ बनाता है।
हमारे परिचय को सारांशित करते हुए, हम ध्यान दें कि OLAP क्यूब्स का उपयोग किसी कंपनी के प्रबंधन को और अधिक बढ़ा सकता है उच्च स्तर. पदानुक्रम के सभी स्तरों पर विश्लेषणात्मक डेटा की एकरूपता, उनकी विश्वसनीयता, जटिलता, संकेतक बनाने और संशोधित करने में आसानी, व्यक्तिगत सेटिंग्स, डेटा प्रोसेसिंग की उच्च गति, और अंत में, वैकल्पिक एनालिटिक्स पथ (एप्लिकेशन प्रोग्रामर, स्वतंत्र) का समर्थन करने पर खर्च किए गए पैसे और समय की बचत एक कर्मचारी की गणना), बड़ी रूसी कंपनियों के अभ्यास में OLAP-क्यूब्स के उपयोग की खुली संभावनाएँ।
OLTP + OLAP: कॉर्पोरेट प्रबंधन श्रृंखला में फीडबैक लूप
अब OLAP क्यूब्स के सामान्य विचार और कॉर्पोरेट प्रबंधन श्रृंखला में उनके आवेदन पर विचार करें। OLAP (ऑनलाइन एनालिटिकल प्रोसेसिंग) शब्द ब्रिटिश गणितज्ञ एडगर कॉड द्वारा उनके पहले के शब्द OLTP (ऑनलाइन ट्रांजैक्शन प्रोसेसिंग) के अलावा पेश किया गया था। इस पर बाद में चर्चा की जाएगी, लेकिन ई। कॉड ने, न केवल शर्तों को प्रस्तावित किया, बल्कि ओएलटीपी और ओएलएपी के गणितीय सिद्धांतों को भी प्रस्तावित किया। विवरण में जाने के बिना, ओएलटीपी की आधुनिक व्याख्या में एक रिलेशनल डेटाबेस है, जिसे पंजीकरण, भंडारण और जानकारी प्राप्त करने के लिए एक तंत्र के रूप में माना जाता है।
समाधान पद्धति
1C7, 1C8, MS Dynamics AX जैसे ERP-सिस्टम (एंटरप्राइस रिसोर्स प्लानिंग) में उपयोगकर्ता-उन्मुख सॉफ़्टवेयर इंटरफ़ेस (दस्तावेज़ों का इनपुट और सुधार, आदि), और आज प्रस्तुत जानकारी को संग्रहीत करने और पुनः प्राप्त करने के लिए एक रिलेशनल डेटाबेस (DB) है। सॉफ्टवेयर उत्पादोंएमएस एसक्यूएल सर्वर (एसएस) टाइप करें।
ध्यान दें कि ईआरपी सिस्टम के डेटाबेस में पंजीकृत जानकारी वास्तव में एक बहुत ही मूल्यवान संसाधन है। मुद्दा केवल यह नहीं है कि पंजीकृत जानकारी निगम के वर्तमान वर्कफ़्लो (दस्तावेज़ जारी करना, उनका सुधार, मुद्रण और सुलह की संभावना, आदि) प्रदान करती है और न केवल गणना की संभावना वित्तीय विवरण(कर, लेखापरीक्षा, आदि)। प्रबंधन के दृष्टिकोण से, यह बहुत अधिक महत्वपूर्ण है कि एक OLTP सिस्टम (रिलेशनल डेटाबेस), वास्तव में, पूर्ण आकार में निगम की गतिविधियों का एक वास्तविक डिजिटल मॉडल है।
लेकिन प्रक्रिया का प्रबंधन करने के लिए, इसके बारे में जानकारी दर्ज करना ही काफी नहीं है। प्रक्रिया को संख्यात्मक संकेतकों (केपीआई) की एक प्रणाली के रूप में प्रस्तुत किया जाना चाहिए जो इसके पाठ्यक्रम की विशेषता है। इसके अलावा, संकेतकों के लिए मूल्यों की स्वीकार्य श्रेणियों को परिभाषित किया जाना चाहिए। और केवल अगर सूचक का मूल्य स्वीकार्य अंतराल से परे चला जाता है, तो एक नियंत्रण कार्रवाई का पालन करना चाहिए।
प्रबंधन के ऐसे तर्क (या पौराणिक कथाओं) के संबंध में ("विचलन द्वारा प्रबंधन") अभिसरण और प्राचीन यूनानी दार्शनिकप्लेटो, जिन्होंने एक हेल्समैन (साइबर नाक) की छवि बनाई, जो नाव के पाठ्यक्रम से विचलित होने पर ऊर पर झुक जाता है, और अमेरिकी गणितज्ञ नॉर्बर्ट वीनर, जिन्होंने कंप्यूटर के युग की पूर्व संध्या पर साइबरनेटिक्स का विज्ञान बनाया।
ओएलटीपी पद्धति का उपयोग करके जानकारी रिकॉर्ड करने की सामान्य प्रणाली के अलावा, एक और प्रणाली की आवश्यकता है - एकत्रित जानकारी के विश्लेषण के लिए एक प्रणाली। यह ऐड-इन, जो कंट्रोल लूप में प्रबंधन और कंट्रोल ऑब्जेक्ट के बीच फीडबैक की भूमिका निभाता है, एक OLAP सिस्टम या, संक्षेप में, एक OLAP क्यूब है।
OLAP के एक सॉफ्टवेयर कार्यान्वयन के रूप में, हम MS विश्लेषण सेवा उपयोगिता पर विचार करेंगे, जो MS SQL सर्वर के मानक वितरण का हिस्सा है, जिसे SSAS के रूप में संक्षिप्त किया गया है। ध्यान दें कि E. Codd के विचार के अनुसार, एनालिटिक्स में OLAP क्यूब को कार्रवाई की वही विस्तृत स्वतंत्रता देनी चाहिए जो OLTP सिस्टम और रिलेशनल डेटाबेस (SQL सर्वर) सूचनाओं को संग्रहीत करने और पुनर्प्राप्त करने में देते हैं।
ओएलएपी लॉजिस्टिक्स
अब आइए बाहरी उपकरणों, अनुप्रयोगों और तकनीकी संचालन के विशिष्ट विन्यास पर विचार करें, जिस पर OLAP क्यूब का स्वचालित संचालन आधारित है।
हम मान लेंगे कि निगम एक ईआरपी सिस्टम का उपयोग करता है, उदाहरण के लिए, 1C7 या 1C8, जिसके भीतर जानकारी सामान्य तरीके से दर्ज की जाती है। इस ईआरपी-सिस्टम का डेटाबेस एक निश्चित सर्वर पर स्थित है और एमएस एसक्यूएल सर्वर द्वारा बनाए रखा जाता है।
हम यह भी मानेंगे कि सॉफ़्टवेयर किसी अन्य सर्वर पर स्थापित है, जिसमें MS विश्लेषण सेवाओं (SSAS) उपयोगिता के साथ MS SQL सर्वर, साथ ही साथ MS SQL सर्वर प्रबंधन स्टूडियो, MS C#, MS Excel और MS Visual Studio प्रोग्राम शामिल हैं। ये प्रोग्राम मिलकर आवश्यक संदर्भ बनाते हैं: OLAP क्यूब डेवलपर के लिए उपकरण और आवश्यक इंटरफेस।
एसएसएएस सर्वर में फ्रीवेयर ब्लैट स्थापित है, जिसे (पैरामीटर के साथ) कहा जाता है कमांड लाइनऔर डाक सेवाएं प्रदान करना।
कर्मचारी कार्यस्थलों पर, भीतर स्थानीय नेटवर्क, अन्य बातों के अलावा, एमएस एक्सेल प्रोग्राम (संस्करण 2003 या उच्चतर) स्थापित हैं, साथ ही, संभवतः, एमएस एक्सेल को एमएस विश्लेषण सेवाओं के साथ काम करने के लिए सक्षम करने के लिए एक विशेष ड्राइवर (जब तक कि संबंधित ड्राइवर पहले से ही एमएस एक्सेल में शामिल नहीं है)।
निश्चितता के लिए, हम मानेंगे कि कर्मचारियों के कार्यस्थानों में Windows XP ऑपरेटिंग सिस्टम स्थापित है, और सर्वरों में Windows Server 2008 स्थापित है। इसके अलावा, MS SQL Server 2005 को SQL सर्वर और एंटरप्राइज़ संस्करण (EE) के रूप में उपयोग करने दें या डेवलपर संस्करण (डीई)। इन संस्करणों में, तथाकथित का उपयोग करना संभव है। "अर्ध-योगात्मक उपाय", अर्थात। अतिरिक्त समग्र कार्य (सांख्यिकी) नियमित रकम के अलावा (जैसे चरम या औसत मूल्य)।
OLAP घन डिजाइन (OLAP घनवाद)
आइए OLAP क्यूब के डिज़ाइन के बारे में कुछ शब्द बताते हैं। आँकड़ों की भाषा में, एक OLAP क्यूब सभी आवश्यक वर्गों में गणना किए गए प्रदर्शन संकेतकों का एक सेट है, उदाहरण के लिए, खरीदारों द्वारा वर्गों में, माल द्वारा, तिथियों द्वारा, आदि में एक शिपमेंट संकेतक। OLAP क्यूब्स पर रूसी साहित्य में अंग्रेजी से सीधे अनुवाद के कारण, संकेतक को "उपाय" कहा जाता है, और कटौती को "आयाम" कहा जाता है। यह गणितीय रूप से सही है, लेकिन वाक्य-विन्यास और शब्दार्थ की दृष्टि से बहुत सफल अनुवाद नहीं है। रूसी शब्द "माप", "माप", "आयाम" लगभग अर्थ और वर्तनी में भिन्न नहीं होते हैं, जबकि अंग्रेजी "माप" और "आयाम" वर्तनी और अर्थ दोनों में भिन्न हैं। इसलिए, हम "संकेतक" और "कट" के अर्थ में समान पारंपरिक रूसी सांख्यिकीय शब्द पसंद करते हैं।
OLTP सिस्टम के संबंध में OLAP क्यूब के सॉफ़्टवेयर कार्यान्वयन के लिए कई विकल्प हैं जहाँ डेटा लॉग किया जाता है। हम केवल एक योजना पर विचार करेंगे, सबसे सरल, सबसे विश्वसनीय और सबसे तेज़।
इस स्कीमा में, OLAP और OLTP में सामान्य तालिकाएँ नहीं होती हैं, और OLAP विश्लेषणों की गणना उपयोग चरण से पहले क्यूब अपडेट (प्रक्रिया) चरण में यथासंभव विस्तृत रूप से की जाती है। इस योजना को MOLAP (बहुआयामी OLAP) कहा जाता है। इसके नुकसान ईआरपी और उच्च मेमोरी लागत के साथ अतुल्यकालिक हैं।
हालांकि औपचारिक रूप से एक OLAP क्यूब एक ईआरपी सिस्टम रिलेशनल डेटाबेस के सभी (हजारों) तालिकाओं को डेटा स्रोत के रूप में और उनके सभी (सैकड़ों) क्षेत्रों को संकेतक या अनुभागों के रूप में उपयोग करके बनाया जा सकता है, वास्तव में ऐसा नहीं किया जाना चाहिए। विपरीतता से। क्यूब में लोड करने के लिए, "शोकेस" या "वेयरहाउस" (गोदाम) नामक एक अलग डेटाबेस तैयार करना अधिक सही है।
यह मामला ऐसा क्यों है इसके कई कारण हैं।
- पहले तो, OLAP क्यूब को टेबल से लिंक करना वास्तविक आधारडेटा निश्चित रूप से तकनीकी समस्याएं पैदा करेगा। किसी तालिका में डेटा बदलने से क्यूब का रिफ्रेश हो सकता है, और क्यूब को रिफ्रेश करना एक तेज प्रक्रिया नहीं है, इसलिए क्यूब स्थायी पुनर्निर्माण की स्थिति में होगा; उसी समय, क्यूब को अपडेट करने की प्रक्रिया ईआरपी सिस्टम में डेटा दर्ज करने में उपयोगकर्ताओं के काम को धीमा करते हुए, डेटाबेस तालिकाओं के डेटा को ब्लॉक (पढ़ने के दौरान) कर सकती है।
- दूसरे, बहुत सारे संकेतक और कटौती की उपस्थिति नाटकीय रूप से सर्वर पर क्यूब के भंडारण क्षेत्र को बढ़ाएगी। आइए यह न भूलें कि OLAP क्यूब न केवल प्रारंभिक डेटा को संग्रहीत करता है, जैसा कि OLTP सिस्टम में होता है, बल्कि सभी संभावित वर्गों (और यहां तक कि सभी वर्गों के सभी संयोजनों पर भी) का सारांश दिया जाता है। इसके अलावा, क्यूब को अपडेट करने की गति और अंततः एनालिटिक्स और उनके आधार पर उपयोगकर्ता रिपोर्ट बनाने और अपडेट करने की गति तदनुसार धीमी हो जाएगी।
- तीसरा, बहुत सारे क्षेत्र (उपाय और पहलू) OLAP डेवलपर इंटरफ़ेस में समस्याएँ पैदा करेंगे, क्योंकि तत्वों की सूची अंतहीन हो जाएगी।
- चौथा, एक OLAP घन डेटा अखंडता उल्लंघनों के प्रति बहुत संवेदनशील है। क्यूब फ़ील्ड्स की लिंक संरचना में निर्दिष्ट लिंक द्वारा कुंजी डेटा स्थित नहीं होने पर क्यूब का निर्माण नहीं किया जा सकता है। अखंडता का अस्थायी या स्थायी उल्लंघन, ERP सिस्टम के डेटाबेस में रिक्त फ़ील्ड सामान्य हैं, लेकिन यह स्पष्ट रूप से OLAP के लिए उपयुक्त नहीं है।
आप यह भी जोड़ सकते हैं कि लोड साझा करने के लिए ERP सिस्टम और OLAP क्यूब अलग-अलग सर्वर पर स्थित होने चाहिए। लेकिन फिर, यदि OLAP और OLTP के लिए सामान्य तालिकाएँ हैं, तो नेटवर्क ट्रैफ़िक की समस्या भी है। इस मामले में व्यावहारिक रूप से अघुलनशील समस्याएं दिखाई देती हैं यदि कई विषम ईआरपी सिस्टम (1C7, 1C8, MS Dynamics AX) को एक OLAP क्यूब में समेकित करना आवश्यक है।
संभवतया, तकनीकी समस्याओं को और अधिक ढेर करना संभव है। लेकिन सबसे महत्वपूर्ण बात, याद रखें कि, OLTP के विपरीत, OLAP डेटा दर्ज करने और संग्रहीत करने का साधन नहीं है, बल्कि एक विश्लेषण उपकरण है। इसका मतलब है कि ईआरपी से ओएलएपी में "बस मामले में" "गंदे" डेटा को लोड और लोड करने की कोई आवश्यकता नहीं है। इसके विपरीत, आपको पहले कम से कम KPI सिस्टम स्तर पर एक कंपनी के प्रबंधन के लिए एक अवधारणा विकसित करनी होगी, और फिर OLAP क्यूब के समान सर्वर पर स्थित एक एप्लिकेशन डेटा वेयरहाउस (वेयरहाउस) को डिज़ाइन करना होगा और इसमें ERP की थोड़ी सी परिष्कृत मात्रा शामिल होगी। प्रबंधन के लिए आवश्यक डेटा।
प्रचार नहीं कर रहा बुरी आदतें, OLTP के संबंध में OLAP-क्यूब की तुलना प्रसिद्ध "एलेम्बिक क्यूब" से की जा सकती है, जिसके माध्यम से एक वास्तविक पंजीकरण के "किण्वित द्रव्यमान" से एक "स्वच्छ उत्पाद" निकाला जाता है।
तो, हमें पता चला कि OLAP के लिए डेटा स्रोत एक विशेष डेटाबेस (वेयरहाउस) है जो OLAP के समान सर्वर पर स्थित है। मूल रूप से, इसका मतलब दो चीजें हैं। सबसे पहले, ऐसी विशेष प्रक्रियाएँ होनी चाहिए जो ERP डेटाबेस से एक वेयरहाउस बनाएगी। दूसरे, OLAP क्यूब अपने ERP सिस्टम के साथ अतुल्यकालिक है।
उपरोक्त को ध्यान में रखते हुए, हम कम्प्यूटेशनल प्रक्रिया की वास्तुकला के निम्नलिखित संस्करण का प्रस्ताव करते हैं।
समाधान वास्तुकला
अलग-अलग सर्वरों पर एक निश्चित निगम (होल्डिंग) के कई ईआरपी सिस्टम होने दें, जिसके लिए हम एक OLAP क्यूब के भीतर समेकित डेटा को देखना चाहेंगे। हम इस बात पर जोर देते हैं कि वर्णित तकनीक में, हम OLAP क्यूब के डिज़ाइन को अपरिवर्तित रखते हुए, गोदाम स्तर पर ERP सिस्टम के डेटा को जोड़ते हैं।
OLAP सर्वर पर, हम इन सभी ERP सिस्टम के डेटाबेस की इमेज (रिक्त कॉपी) बनाते हैं। इन खाली प्रतियों के लिए, हम समय-समय पर (रात में) संबंधित सक्रिय रूप से चल रहे ईआरपी के डेटाबेस की आंशिक प्रतिकृति करते हैं।
अगला, एसपी (संग्रहीत कार्यविधि) लॉन्च किया गया है, जो ईआरपी सिस्टम के डेटाबेस के आंशिक प्रतिकृतियों के आधार पर, नेटवर्क ट्रैफ़िक के बिना एक ही OLAP सर्वर पर, स्टोरेज (वेयरहाउस) बनाता है (या फिर से भरता है) - OLAP का डेटा स्रोत घन।
फिर वेयरहाउस डेटा के अनुसार क्यूब को अपडेट करने / बनाने की मानक प्रक्रिया शुरू की जाती है (SSAS इंटरफ़ेस में प्रक्रिया संचालन)।
आइए प्रौद्योगिकी के कुछ पहलुओं पर टिप्पणी करें। एसपी किस तरह का काम करते हैं?
आंशिक प्रतिकृति के परिणामस्वरूप, OLAP सर्वर पर कुछ ERP सिस्टम की छवि में वास्तविक डेटा दिखाई देता है। वैसे, आंशिक प्रतिकृति दो तरह से की जा सकती है।
सबसे पहले, ईआरपी सिस्टम के डेटाबेस में सभी तालिकाओं में, आंशिक प्रतिकृति के दौरान, केवल वे ही कॉपी किए जाते हैं जिनकी आवश्यकता गोदाम बनाने के लिए होती है। इसे तालिका नामों की एक निश्चित सूची द्वारा नियंत्रित किया जाता है।
दूसरे, आंशिक प्रतिकृति का अर्थ यह भी हो सकता है कि तालिका के सभी फ़ील्ड कॉपी नहीं किए गए हैं, लेकिन केवल वे जो वेयरहाउस बनाने में शामिल हैं। कॉपी किए जाने वाले फ़ील्ड की सूची या तो एसपी में कॉपी छवि से निर्दिष्ट या गतिशील रूप से बनाई गई है (यदि तालिका की प्रतिलिपि में प्रारंभ में सभी फ़ील्ड शामिल नहीं हैं)।
बेशक, यह संभव है कि संपूर्ण तालिका पंक्तियों की प्रतिलिपि न बनाई जाए, बल्कि केवल नए रिकॉर्ड जोड़े जाएं। हालांकि, ईआरपी संशोधन "बैकडेटिंग" के लिए लेखांकन करते समय यह एक गंभीर असुविधा पैदा करता है, जो अक्सर वास्तविक जीवन प्रणालियों में पाया जाता है। इसलिए, बिना किसी देरी के, सभी रिकॉर्ड्स को कॉपी करना (या किसी तारीख से शुरू होने वाले "पूंछ" को अपडेट करना) आसान है।
इसके अलावा, एसपी का मुख्य कार्य ईआरपी सिस्टम से डेटा को वेयरहाउस प्रारूप में परिवर्तित करना है। यदि केवल एक ईआरपी-सिस्टम है, तो परिवर्तन का कार्य मुख्य रूप से आवश्यक डेटा की प्रतिलिपि बनाने और संभवतः सुधार करने के लिए कम हो जाता है। लेकिन अगर आपको एक ही OLAP क्यूब में कई ERP सिस्टम को समेकित करने की आवश्यकता है अलग संरचना, तब परिवर्तन अधिक जटिल हो जाते हैं।
क्यूब में कई अलग-अलग ईआरपी सिस्टम को समेकित करने का कार्य विशेष रूप से कठिन है, यदि उनकी वस्तुओं (माल, ठेकेदारों, गोदामों, आदि की निर्देशिका) के सेट आंशिक रूप से प्रतिच्छेद करते हैं, तो वस्तुओं का एक ही अर्थ होता है, लेकिन स्वाभाविक रूप से उन्हें अलग-अलग तरीके से वर्णित किया जाता है। निर्देशिका विभिन्न प्रणालियाँ(कोड, पहचानकर्ता, नाम आदि के अर्थ में)।
वास्तव में, ऐसी तस्वीर एक बड़ी होल्डिंग कंपनी में उत्पन्न होती है, जब एक ही प्रकार की कई स्वायत्त कंपनियाँ जो इसे बनाती हैं, लगभग उसी प्रकार की गतिविधियों को लगभग एक ही क्षेत्र में करती हैं, लेकिन अपने स्वयं के और गैर-समन्वित पंजीकरण प्रणालियों का उपयोग करती हैं। इस स्थिति में, वेयरहाउस स्तर पर डेटा को समेकित करते समय, आप सहायक मानचित्रण तालिकाओं के बिना नहीं कर सकते।
आइए वेयरहाउस स्टोरेज आर्किटेक्चर पर कुछ ध्यान दें। आमतौर पर, एक OLAP क्यूब स्कीमा को "स्टार" के रूप में दर्शाया जाता है, अर्थात। निर्देशिकाओं की "किरणों" से घिरी डेटा तालिका के रूप में - द्वितीयक कुंजी मानों की तालिकाएँ। तालिका "संकेतक" का एक ब्लॉक है, संदर्भ पुस्तकें उनकी कटौती हैं। उसी समय, निर्देशिका, बदले में, एक मनमाना असंतुलित पेड़ या एक संतुलित पदानुक्रम हो सकता है, उदाहरण के लिए, माल या प्रतिपक्षों का एक बहु-स्तरीय वर्गीकरण। OLAP क्यूब में, वेयरहाउस से डेटा तालिका के संख्यात्मक फ़ील्ड स्वचालित रूप से "संकेतक" (या उपायों के उपाय) बन जाते हैं, और वर्गों (या आयाम) को द्वितीयक कुंजियों की तालिका के माध्यम से परिभाषित किया जा सकता है।
यह एक दृश्य "शैक्षणिक" वर्णन है। वास्तव में, एक OLAP क्यूब का आर्किटेक्चर बहुत अधिक जटिल हो सकता है।
सबसे पहले, एक गोदाम में कई "तारांकन" शामिल हो सकते हैं, संभवतः सामान्य निर्देशिकाओं के माध्यम से जुड़े हुए हैं। इस स्थिति में, OLAP घन कई घनों (एकाधिक डेटा ब्लॉक) का एक संघ होगा।
दूसरे, तारांकन चिह्न की "किरण" एक निर्देशिका नहीं हो सकती है, बल्कि एक संपूर्ण (श्रेणीबद्ध) फाइल सिस्टम है।
तीसरा, मौजूदा आयामों में कटौती के आधार पर, OLAP डेवलपर इंटरफ़ेस (कहते हैं, कम स्तरों के साथ, स्तरों के एक अलग क्रम के साथ, आदि) का उपयोग करके नए पदानुक्रमित कटौती को परिभाषित किया जा सकता है।
चौथा, नए संकेतक (गणना) को MDX भाषा की अभिव्यक्ति का उपयोग करते हुए मौजूदा संकेतकों और अनुभागों के आधार पर परिभाषित किया जा सकता है। यह ध्यान रखना महत्वपूर्ण है कि नए क्यूब्स, नए संकेतक, नए खंड स्वचालित रूप से मूल तत्वों के साथ पूरी तरह से एकीकृत होते हैं। यह भी ध्यान दिया जाना चाहिए कि खराब रूप से तैयार की गई गणना और पदानुक्रमित कटौती ओएलएपी क्यूब के काम को धीमा कर सकती है।
ओएलएपी के साथ एक इंटरफेस के रूप में एमएस एक्सेल
विशेष रूप से दिलचस्प OLAP क्यूब्स के साथ यूजर इंटरफेस है। स्वाभाविक रूप से, SSAS उपयोगिता ही सबसे पूर्ण इंटरफ़ेस प्रदान करती है। यह एक OLAP क्यूब डेवलपर टूलकिट, एक इंटरैक्टिव रिपोर्ट डिज़ाइनर, और MDX भाषा में प्रश्नों का उपयोग करके OLAP क्यूब के साथ इंटरैक्टिव कार्य के लिए एक विंडो है।
स्वयं SSAS के अलावा, ऐसे कई प्रोग्राम हैं जो OLAP को इंटरफ़ेस प्रदान करते हैं, उनकी कार्यक्षमता को अधिक या कम सीमा तक कवर करते हैं। लेकिन उनमें से एक है, जो हमारी राय में निर्विवाद फायदे हैं। यह एमएस एक्सेल है।
एमएस एक्सेल के साथ इंटरफेस एक विशेष ड्राइवर द्वारा प्रदान किया जाता है, जिसे अलग से डाउनलोड किया जा सकता है या एक्सेल के साथ शामिल किया जा सकता है। इसमें OLAP की सभी कार्यक्षमता शामिल नहीं है, लेकिन MS Excel संस्करण संख्याओं की वृद्धि के साथ, यह कवरेज व्यापक होता जा रहा है (जैसे, MS Excel 2007 में एक KPI ग्राफ़िक प्रकट होता है, जो MS Excel 2003, आदि में नहीं था)।
बेशक, काफी पूर्ण कार्यक्षमता के अलावा, एमएस एक्सेल का मुख्य लाभ इस कार्यक्रम का सर्वव्यापी वितरण और कार्यालय उपयोगकर्ताओं के विशाल बहुमत के साथ घनिष्ठ परिचित है। इस अर्थ में, अन्य इंटरफ़ेस प्रोग्रामों के विपरीत, फर्म को अतिरिक्त रूप से कुछ भी हासिल करने की आवश्यकता नहीं होती है और न ही किसी को अतिरिक्त रूप से प्रशिक्षित करने की आवश्यकता होती है।
OLAP के साथ एक इंटरफ़ेस के रूप में MS Excel का बड़ा लाभ OLAP रिपोर्ट में प्राप्त डेटा के आगे स्वतंत्र प्रसंस्करण की संभावना है (अर्थात, उसी एक्सेल की अन्य शीट्स पर OLAP से प्राप्त डेटा के अध्ययन की निरंतरता, अब इसका उपयोग नहीं कर रहा है) OLAP टूल, लेकिन सामान्य एक्सेल टूल का उपयोग करके)।
रात्रिकालीन फेक्यूबी उपचार चक्र
अब आइए OLAP ऑपरेशन के दैनिक (रात्रिकालीन) कंप्यूटिंग चक्र का वर्णन करें। गणना फैक्यूबी प्रोग्राम के नियंत्रण में की जाती है, जिसे C # 2005 में लिखा गया है और वेयरहाउस और SSAS वाले सर्वर पर टास्क शेड्यूलर का उपयोग करके लॉन्च किया गया है। शुरुआत में, facubi इंटरनेट का उपयोग करता है और वर्तमान विनिमय दरों को पढ़ता है (मुद्रा में कई संकेतकों का प्रतिनिधित्व करने के लिए उपयोग किया जाता है)। अगला, निम्नलिखित चरण किए जाते हैं।
सबसे पहले, facubi ने SPs लॉन्च किए जो स्थानीय नेटवर्क पर उपलब्ध विभिन्न ERP सिस्टम (होल्डिंग एलिमेंट्स) की आंशिक डेटाबेस प्रतिकृति करते हैं। प्रतिकृति, जैसा कि हमने कहा, पूर्व-तैयार "यार्ड" पर किया जाता है - एसएसएएस सर्वर पर स्थित दूरस्थ ईआरपी सिस्टम की छवियां।
दूसरे, एसपी के माध्यम से, ईआरपी प्रतिकृतियों से वेयरहाउस स्टोरेज तक एक मैपिंग की जाती है - एक विशेष डीबी जो ओएलएपी क्यूब डेटा का स्रोत है और एसएसएएस सर्वर पर स्थित है। यह तीन मुख्य कार्य पूरा करता है:
- ईआरपी डेटाआवश्यक घन स्वरूपों के अंतर्गत लाए जाते हैं; हम टेबल और टेबल फील्ड के बारे में बात कर रहे हैं। (कभी-कभी आवश्यक तालिका को कई एमएस एक्सेल शीट से "मोल्ड" करने की आवश्यकता होती है।) इसी तरह के डेटा का अलग-अलग ईआरपी में एक अलग प्रारूप हो सकता है, उदाहरण के लिए, 1C7 निर्देशिकाओं में प्रमुख आईडी फ़ील्ड में लंबाई 8 का 36-वर्ण कोड होता है। , और 1C8 निर्देशिकाओं में _idrref फ़ील्ड - 32 की लंबाई के साथ हेक्साडेसिमल संख्या;
- प्रसंस्करण के दौरान डेटा का तार्किक नियंत्रण किया जाता है (जहां संभव हो, लापता डेटा के स्थान पर "डिफ़ॉल्ट" डिफ़ॉल्ट निर्धारित करने सहित) और अखंडता नियंत्रण, अर्थात। संबंधित क्लासिफायर में प्राथमिक और द्वितीयक कुंजियों की उपस्थिति की जाँच करना;
- कोड समेकन विभिन्न ईआरपी में समान अर्थ रखने वाली वस्तुएं। उदाहरण के लिए, विभिन्न ईआरपी की निर्देशिकाओं के संबंधित तत्वों का एक ही अर्थ हो सकता है, मान लें कि यह एक ही प्रतिपक्ष है। मैपिंग टेबल बनाकर कोड को समेकित करने का कार्य हल किया जाता है, जहां एक ही वस्तु के विभिन्न कोड एकता में लाए जाते हैं।
तीसरा, facubi मानक प्रक्रिया घन डेटा अद्यतन प्रक्रिया (SSAS उपयोगिता प्रक्रियाओं से) लॉन्च करता है।
जाँचकर्ताओं के अनुसार, प्रसंस्करण चरणों की प्रगति के बारे में facubi ई-मेल संदेश भेजता है।
facubi को निष्पादित करने के बाद, टास्क शेड्यूलर बारी-बारी से कई एक्सेल फाइल लॉन्च करता है, जिसमें OLAP क्यूब इंडिकेटर्स के आधार पर रिपोर्ट्स प्री-क्रिएट की जाती हैं। जैसा कि हमने कहा, ओएलएपी क्यूब्स (एसएसएएस के साथ) के साथ काम करने के लिए एमएस एक्सेल में एक विशेष प्रोग्रामिंग इंटरफ़ेस (अलग से डाउनलोड करने योग्य या अंतर्निहित ड्राइवर) है। जब आप एमएस एक्सेल शुरू करते हैं, तो एमएस वीबीए (जैसे मैक्रोज़) पर प्रोग्राम शामिल होते हैं, जो रिपोर्ट में डेटा का अद्यतन प्रदान करते हैं; यदि आवश्यक हो तो रिपोर्ट को संशोधित किया जाता है और चेकलिस्ट के अनुसार उपयोगकर्ताओं को मेल (ब्लैट प्रोग्राम) द्वारा भेजा जाता है।
SSAS सर्वर तक पहुंच रखने वाले स्थानीय नेटवर्क उपयोगकर्ता OLAP क्यूब के लिए कॉन्फ़िगर की गई "लाइव" रिपोर्ट प्राप्त करेंगे। (सैद्धांतिक रूप से, वे स्वयं, बिना किसी मेल के, अपने स्थानीय कंप्यूटरों पर मौजूद MS Excel में OLAP रिपोर्ट को अपडेट कर सकते हैं।) स्थानीय नेटवर्क के बाहर के उपयोगकर्ता या तो मूल रिपोर्ट प्राप्त करेंगे, लेकिन सीमित कार्यक्षमता के साथ, या उनके लिए (OLAP रिपोर्ट अपडेट करने के बाद) MS Excel में) विशेष "मृत" रिपोर्ट की गणना की जाएगी जो SSAS सर्वर से संपर्क नहीं करती हैं।
परिणामों का मूल्यांकन
हमने ऊपर OLTP और OLAP की अतुल्यकालिकता के बारे में बात की। प्रौद्योगिकी के विचारित संस्करण में, OLAP घन अद्यतन चक्र रात में किया जाता है (कहते हैं, यह 1 बजे शुरू होता है)। इसका अर्थ है कि वर्तमान कार्य दिवस में, उपयोगकर्ता कल के डेटा के साथ काम करते हैं। क्योंकि OLAP एक लॉगिंग टूल नहीं है (दस्तावेज़ का नवीनतम संस्करण देखें), लेकिन एक प्रबंधन टूल (प्रक्रिया की प्रवृत्ति को समझें), यह बैकलॉग आमतौर पर महत्वपूर्ण नहीं है। हालाँकि, यदि आवश्यक हो, तो क्यूब आर्किटेक्चर (MOLAP) के वर्णित संस्करण में भी, दिन में कई बार अपडेट करना संभव है।
अद्यतन प्रक्रियाओं का निष्पादन समय OLAP क्यूब की डिज़ाइन सुविधाओं (अधिक या कम जटिलता, संकेतकों और वर्गों की अधिक या कम सफल परिभाषा) और बाहरी OLTP सिस्टम के डेटाबेस की मात्रा पर निर्भर करता है। अनुभव के अनुसार, गोदाम बनाने की प्रक्रिया में कई मिनट से लेकर दो घंटे तक का समय लगता है, क्यूब (प्रक्रिया) को अपडेट करने की प्रक्रिया में 1 से 20 मिनट तक का समय लगता है। हम जटिल OLAP क्यूब्स के बारे में बात कर रहे हैं जो दर्जनों स्टार संरचनाओं को जोड़ते हैं, उनके लिए दर्जनों सामान्य "किरणें" (संदर्भ कटौती), सैकड़ों संकेतक के बारे में। शिपिंग दस्तावेजों द्वारा बाहरी ईआरपी सिस्टम के डेटाबेस की मात्रा का अनुमान लगाते हुए, हम सैकड़ों हजारों दस्तावेजों और तदनुसार, प्रति वर्ष लाखों उत्पाद लाइनों के बारे में बात कर रहे हैं। उपयोगकर्ता के लिए रुचि के प्रसंस्करण की ऐतिहासिक गहराई तीन से पांच वर्ष थी।
वर्णित तकनीक का उपयोग कई बड़े निगमों में किया जाता है: 2008 से रूसी मछली कंपनी (आरआरके) और रूसी सागर कंपनी (आरएम) में, 2012 से सांता ब्रेमर कंपनी (एसबी) में। कुछ निगम मुख्य रूप से व्यापार-क्रय फर्म (आरआरके) हैं, अन्य उत्पादन फर्म हैं (मोल्दोवा गणराज्य और सुरक्षा परिषद में मछली और समुद्री खाद्य प्रसंस्करण संयंत्र)। सभी निगम बड़ी होल्डिंग हैं जो स्वतंत्र और विभिन्न कंप्यूटर लेखा प्रणालियों के साथ कई कंपनियों को एकजुट करते हैं - मानक ईआरपी सिस्टम जैसे 1C7 और 1C8 से लेकर DBF और एक्सेल पर आधारित "अवशेष" लेखा प्रणाली तक। मैं यह जोड़ूंगा कि OLAP क्यूब्स (विकास के चरण को ध्यान में रखे बिना) के संचालन के लिए वर्णित तकनीक को या तो विशेष कर्मचारियों की आवश्यकता नहीं है, या एक पूर्णकालिक व्यापार विश्लेषक की जिम्मेदारियों में शामिल है। यह कार्य वर्षों से स्वत: मोड में घूम रहा है, दैनिक रूप से अप-टू-डेट रिपोर्टिंग के साथ कॉर्पोरेट कर्मचारियों की विभिन्न श्रेणियों की आपूर्ति करता है।
समाधान के पक्ष और विपक्ष
जैसा कि अनुभव से पता चलता है, प्रस्तावित समाधान का संस्करण काफी विश्वसनीय और संचालित करने में आसान है। यह आसानी से संशोधित किया जाता है (नए ईआरपी को जोड़ना/डिस्कनेक्ट करना, नए संकेतक और अनुभाग बनाना, एक्सेल रिपोर्ट और उनकी मेलिंग सूची बनाना और संशोधित करना) फैक्यूबी नियंत्रण कार्यक्रम के आक्रमण के साथ।
OLAP के साथ एक इंटरफ़ेस के रूप में MS Excel पर्याप्त अभिव्यक्ति प्रदान करता है और विभिन्न श्रेणियों के कार्यालय कर्मचारियों को OLAP तकनीक से शीघ्रता से जुड़ने की अनुमति देता है। उपयोगकर्ता दैनिक "मानक" OLAP रिपोर्ट प्राप्त करता है; OLAP के साथ MS Excel इंटरफ़ेस का उपयोग करके, MS Excel में स्वतंत्र रूप से OLAP रिपोर्ट बना सकते हैं। इसके अलावा, उपयोगकर्ता स्वतंत्र रूप से अपने एमएस एक्सेल की सामान्य क्षमताओं का उपयोग करके OLAP रिपोर्ट की जानकारी का पता लगाना जारी रख सकता है।
एक "परिष्कृत" वेयरहाउस डेटाबेस, जिसमें कई विषम ईआरपी सिस्टम समेकित होते हैं (घन निर्माण के दौरान), यहां तक कि बिना किसी OLAP के, (SSAS सर्वर पर, Transact SQL क्वेरी विधि या SP विधि, आदि का उपयोग करके) को हल करने की अनुमति देता है। बहुत सारे लागू प्रबंधन कार्य। याद रखें कि मूल ईआरपी के डेटाबेस संरचनाओं की तुलना में वेयरहाउस डेटाबेस संरचना एकीकृत और बहुत सरल (तालिकाओं की संख्या और तालिका फ़ील्ड की संख्या के संदर्भ में) है।
हम विशेष रूप से ध्यान देते हैं कि हमारे प्रस्तावित समाधान में एक ओलाप क्यूब में विभिन्न ईआरपी सिस्टम को समेकित करने की संभावना है। यह आपको पूरे होल्डिंग के लिए एनालिटिक्स प्राप्त करने और एनालिटिक्स में लंबी अवधि की निरंतरता बनाए रखने की अनुमति देता है, जब एक निगम 1C7 से 1C8 की ओर बढ़ते हुए किसी अन्य ERP अकाउंटिंग सिस्टम में जाता है।
हमने MOLAP क्यूब मॉडल का इस्तेमाल किया। इस मॉडल के फायदे संचालन में विश्वसनीयता और उपयोगकर्ता अनुरोधों को संसाधित करने की उच्च गति हैं। विपक्ष - अतुल्यकालिक OLAP और OLTP, साथ ही OLAP को संग्रहीत करने के लिए बड़ी मात्रा में मेमोरी।
अंत में, आइए OLAP के पक्ष में एक और तर्क दें, जो शायद मध्य युग में अधिक उपयुक्त होता। क्योंकि इसकी परीक्षण शक्ति अधिकार पर टिकी हुई है। विनम्र, स्पष्ट रूप से कम आंका गया ब्रिटिश गणितज्ञ ई. कॉड ने 60 के दशक के अंत में रिलेशनल डेटाबेस के सिद्धांत को विकसित किया। इस सिद्धांत की ताकत इतनी थी कि अब, 50 वर्षों के बाद, SQL के अलावा एक गैर-संबंधपरक डेटाबेस और डेटाबेस क्वेरी भाषा खोजना पहले से ही मुश्किल है।
रिलेशनल डेटाबेस के सिद्धांत पर आधारित OLTP तकनीक ई. कॉड का पहला विचार था। वास्तव में, OLAP क्यूब्स की अवधारणा उनका दूसरा विचार है, जिसे उन्होंने 90 के दशक की शुरुआत में व्यक्त किया था। यहां तक कि अगर आप गणितज्ञ नहीं हैं, तो आप दूसरे विचार के पहले की तरह ही प्रभावी होने की उम्मीद कर सकते हैं। यानी कंप्यूटर एनालिटिक्स के संदर्भ में, OLAP विचार जल्द ही दुनिया भर में छा जाएंगे और अन्य सभी को हटा देंगे। केवल इसलिए कि एनालिटिक्स का विषय OLAP में अपना संपूर्ण गणितीय समाधान पाता है, और यह समाधान एनालिटिक्स के व्यावहारिक कार्य के लिए "पर्याप्त" (बी। स्पिनोज़ा का शब्द) है। स्पिनोज़ा में "पर्याप्त रूप से" का अर्थ है कि स्वयं भगवान भी एक बेहतर विचार के साथ नहीं आ सकते थे ...
- लार्सन बी। माइक्रोसॉफ्ट एसक्यूएल सर्वर 2005 में बिजनेस इंटेलिजेंस का विकास। - सेंट पीटर्सबर्ग: "पिटर", 2008।
- Codd E. डेटा बेस सबलैंग्वेज, डेटा बेस सिस्टम, कोर्टेंट कंप्यूटर साइंस सम्पोसिया सीरीज़ 1972 की रिलेशनल कम्प्लीटनेस, वी। 6, एंगलवुड क्लिफ्स, एन.वाई., प्रेंटिस-हॉल।
के साथ संपर्क में
आज OLAP क्या है, सामान्य तौर पर, हर विशेषज्ञ जानता है। कम से कम "ओएलएपी" और "बहुआयामी डेटा" की अवधारणाएं हमारे दिमाग में मजबूती से जुड़ी हुई हैं। फिर भी, यह तथ्य कि इस विषय को फिर से उठाया जा रहा है, मुझे उम्मीद है, अधिकांश पाठकों द्वारा अनुमोदित किया जाएगा, क्योंकि विचार समय के साथ पुराना नहीं होने के लिए, आपको समय-समय पर संवाद करने की आवश्यकता है स्मार्ट लोगया किसी अच्छे प्रकाशन में लेख पढ़ें...
डेटा वेयरहाउस (उद्यम की सूचना संरचना में OLAP का स्थान)
"OLAP" शब्द "डेटा वेयरहाउस" (डेटा वेयरहाउस) शब्द के साथ अटूट रूप से जुड़ा हुआ है।
यहां डेटा वेयरहाउस के "संस्थापक पिता" बिल इनमोन द्वारा तैयार की गई एक परिभाषा है: "एक डेटा वेयरहाउस एक डोमेन-विशिष्ट, समयबद्ध और प्रबंधकीय निर्णय लेने की प्रक्रिया का समर्थन करने के लिए डेटा का अपरिवर्तनीय संग्रह है।"
स्टोरेज में डेटा ऑपरेशनल सिस्टम (OLTP सिस्टम) से आता है, जिसे व्यावसायिक प्रक्रियाओं को स्वचालित करने के लिए डिज़ाइन किया गया है। इसके अलावा, रिपॉजिटरी को बाहरी स्रोतों से भर दिया जा सकता है, जैसे कि सांख्यिकीय रिपोर्ट।
डेटा वेयरहाउस का निर्माण क्यों करें - आखिरकार, उनमें स्पष्ट रूप से अनावश्यक जानकारी होती है जो पहले से ही डेटाबेस या ऑपरेटिंग सिस्टम की फाइलों में "रहती है"? उत्तर छोटा हो सकता है: परिचालन प्रणालियों के डेटा का सीधे विश्लेषण करना असंभव या बहुत कठिन है। यह विभिन्न कारणों से है, जिसमें डेटा का विखंडन, विभिन्न DBMS के स्वरूपों में उनका भंडारण और कॉर्पोरेट नेटवर्क के विभिन्न "कोनों" में शामिल है। लेकिन भले ही उद्यम में सभी डेटा एक केंद्रीय डेटाबेस सर्वर (जो अत्यंत दुर्लभ है) पर संग्रहीत है, विश्लेषक लगभग निश्चित रूप से उनकी जटिल, कभी-कभी भ्रमित करने वाली संरचनाओं को नहीं समझ पाएंगे। लेखक के पास परिचालन प्रणालियों के "कच्चे" डेटा के साथ भूखे विश्लेषकों को "फ़ीड" करने का प्रयास करने का एक दुखद अनुभव है - यह उनके लिए बहुत कठिन निकला।
इस प्रकार, भंडार का कार्य विश्लेषण के लिए "कच्चा माल" एक स्थान पर और एक सरल, समझने योग्य संरचना में प्रदान करना है। राल्फ किमबॉल ने अपनी पुस्तक "द डेटा वेयरहाउस टूलकिट" की प्रस्तावना में लिखा है कि अगर पूरी किताब पढ़ने के बाद पाठक को केवल एक ही बात समझ में आती है कि गोदाम की संरचना सरल होनी चाहिए, तो लेखक अपने कार्य पर विचार करेगा। पुरा होना।
एक और कारण है जो एक अलग भंडारण की उपस्थिति को सही ठहराता है - परिचालन जानकारी के लिए जटिल विश्लेषणात्मक प्रश्न कंपनी के वर्तमान कार्य को धीमा कर देते हैं, लंबे समय तक तालिकाओं को अवरुद्ध करते हैं और सर्वर संसाधनों को जब्त करते हैं।
मेरी राय में, भंडारण आवश्यक रूप से डेटा का विशाल संचय नहीं है - मुख्य बात यह है कि यह विश्लेषण के लिए सुविधाजनक है। सामान्यतया, एक अलग शब्द छोटे भंडारण के लिए अभिप्रेत है - डेटा मार्ट (डेटा कियोस्क), लेकिन हमारे रूसी अभ्यास में आप इसे अक्सर नहीं सुनेंगे।
OLAP एक आसान विश्लेषण उपकरण है
केंद्रीकरण और सुविधाजनक संरचना एक विश्लेषक की जरूरत से बहुत दूर हैं। आखिरकार, उसे अभी भी जानकारी देखने, देखने के लिए एक उपकरण की आवश्यकता है। पारंपरिक रिपोर्ट, यहां तक कि एक रिपॉजिटरी के आधार पर भी बनाई जाती हैं, उनमें एक चीज की कमी होती है - लचीलापन। डेटा के वांछित दृश्य को प्राप्त करने के लिए उन्हें "मुड़", "विस्तृत" या "ढह" नहीं किया जा सकता है। बेशक, आप एक प्रोग्रामर को कॉल कर सकते हैं (यदि वह आना चाहता है), और वह (यदि वह व्यस्त नहीं है) एक नई रिपोर्ट बहुत जल्दी बना देगा - कहते हैं, एक घंटे के भीतर (मैं लिखता हूं और मुझे खुद इस पर विश्वास नहीं है - यह जीवन में इतनी जल्दी नहीं होता है, उसे तीन घंटे दें)। यह पता चला है कि एक विश्लेषक प्रति दिन दो से अधिक विचारों की जांच नहीं कर सकता है। और वह (यदि वह एक अच्छा विश्लेषक है) प्रति घंटे ऐसे कई विचार सोच सकता है। और विश्लेषक जितना अधिक "स्लाइस" और "स्लाइस" डेटा देखता है, उसके पास उतने ही अधिक विचार होते हैं, जो बदले में सत्यापन के लिए अधिक से अधिक नए "स्लाइस" की आवश्यकता होती है। काश उसके पास ऐसा कोई उपकरण होता जो उसे डेटा को आसानी से और आसानी से विस्तारित और संक्षिप्त करने की अनुमति देता! ओएलएपी एक ऐसा उपकरण है।
हालाँकि OLAP डेटा वेयरहाउस की एक आवश्यक विशेषता नहीं है, लेकिन इस डेटा वेयरहाउस में संचित जानकारी का विश्लेषण करने के लिए इसका उपयोग तेजी से किया जाता है।
एक विशिष्ट भंडारण में शामिल घटकों को अंजीर में दिखाया गया है। 1.
चावल। 1. डेटा वेयरहाउस संरचना
परिचालन डेटा को विभिन्न स्रोतों से एकत्र किया जाता है, साफ किया जाता है, एकीकृत किया जाता है और एक रिलेशनल स्टोर में रखा जाता है। साथ ही, वे पहले से ही विभिन्न रिपोर्टिंग टूल का उपयोग करके विश्लेषण के लिए उपलब्ध हैं। फिर डेटा (पूरे या आंशिक रूप से) OLAP विश्लेषण के लिए तैयार किया जाता है। उन्हें एक विशेष OLAP डेटाबेस में लोड किया जा सकता है या एक रिलेशनल स्टोर में छोड़ा जा सकता है। इसका सबसे महत्वपूर्ण तत्व मेटाडेटा है, यानी डेटा की संरचना, प्लेसमेंट और परिवर्तन के बारे में जानकारी। उनके लिए धन्यवाद, विभिन्न भंडारण घटकों की प्रभावी बातचीत सुनिश्चित की जाती है।
सारांशित करते हुए, हम OLAP को गोदाम में संचित डेटा के बहुआयामी विश्लेषण के लिए उपकरणों के एक सेट के रूप में परिभाषित कर सकते हैं। सैद्धांतिक रूप से, OLAP टूल को सीधे परिचालन डेटा या उनकी सटीक प्रतियों पर लागू किया जा सकता है (ताकि परिचालन उपयोगकर्ताओं के साथ हस्तक्षेप न किया जा सके)। लेकिन ऐसा करने से, हम ऊपर वर्णित रेक पर पैर रखने का जोखिम उठाते हैं, यानी परिचालन डेटा का विश्लेषण शुरू करना जो सीधे विश्लेषण के लिए उपयुक्त नहीं हैं।
OLAP की परिभाषा और बुनियादी अवधारणाएँ
आरंभ करने के लिए, आइए समझें: OLAP ऑनलाइन विश्लेषणात्मक प्रसंस्करण है, अर्थात ऑनलाइन डेटा विश्लेषण। OLAP के 12 परिभाषित सिद्धांत 1993 में संबंधपरक डेटाबेस के "आविष्कारक" E. F. Codd द्वारा तैयार किए गए थे। बाद में, इसकी परिभाषा को तथाकथित FASMI परीक्षण में फिर से शामिल किया गया, जिसके लिए साझा बहुआयामी जानकारी () का त्वरित विश्लेषण करने की क्षमता प्रदान करने के लिए एक OLAP एप्लिकेशन की आवश्यकता होती है।
एफएएसएमआई परीक्षण
तेज़(फास्ट) - सूचना के सभी पहलुओं पर विश्लेषण समान रूप से शीघ्रता से किया जाना चाहिए। स्वीकार्य प्रतिक्रिया समय 5 सेकंड या उससे कम है।
विश्लेषण(विश्लेषण) - एप्लिकेशन डेवलपर द्वारा पूर्वनिर्धारित या उपयोगकर्ता द्वारा मनमाने ढंग से परिभाषित बुनियादी प्रकार के संख्यात्मक और सांख्यिकीय विश्लेषण करना संभव होना चाहिए।
साझा(साझा) - एकाधिक उपयोगकर्ताओं के पास डेटा तक पहुंच होनी चाहिए, जबकि संवेदनशील जानकारी तक पहुंच को नियंत्रित किया जाना चाहिए।
बहुआयामी(बहुआयामी) OLAP की मुख्य, सबसे आवश्यक विशेषता है।
जानकारी(सूचना) - एप्लिकेशन को इसकी मात्रा और भंडारण स्थान की परवाह किए बिना किसी भी आवश्यक जानकारी तक पहुंचने में सक्षम होना चाहिए।
OLAP = बहुआयामी दृश्य = घन
OLAP व्यावसायिक जानकारी तक पहुँचने, देखने और विश्लेषण करने का एक सुविधाजनक, उच्च गति वाला साधन प्रदान करता है। उपयोगकर्ता को एक प्राकृतिक, सहज ज्ञान युक्त डेटा मॉडल मिलता है, जो उन्हें बहुआयामी क्यूब्स (क्यूब्स) के रूप में व्यवस्थित करता है। बहुआयामी समन्वय प्रणाली की कुल्हाड़ियाँ विश्लेषण की गई व्यावसायिक प्रक्रिया की मुख्य विशेषताएँ हैं। उदाहरण के लिए, बिक्री के लिए यह एक उत्पाद, क्षेत्र, खरीदार का प्रकार हो सकता है। समय का उपयोग मापों में से एक के रूप में किया जाता है। कुल्हाड़ियों के चौराहों पर - माप (आयाम) - ऐसे डेटा होते हैं जो प्रक्रिया को मात्रात्मक रूप से चिह्नित करते हैं - उपाय (उपाय)। ये टुकड़ों में या मौद्रिक शब्दों में, स्टॉक बैलेंस, लागत आदि में बिक्री की मात्रा हो सकती है। जानकारी का विश्लेषण करने वाला उपयोगकर्ता घन को विभिन्न दिशाओं में "कट" कर सकता है, सारांश प्राप्त कर सकता है (उदाहरण के लिए, वर्षों से) या, इसके विपरीत, विस्तृत (साप्ताहिक) जानकारी और विश्लेषण की प्रक्रिया में उसके दिमाग में आने वाली अन्य जोड़-तोड़ करता है।
अंजीर में दिखाए गए त्रि-आयामी घन में उपायों के रूप में। 2, बिक्री मात्रा का उपयोग किया जाता है, और समय, उत्पाद और स्टोर को माप के रूप में उपयोग किया जाता है। माप विशिष्ट समूहीकरण स्तरों पर प्रस्तुत किए जाते हैं: उत्पादों को श्रेणी के अनुसार समूहीकृत किया जाता है, दुकानों को देश के अनुसार समूहीकृत किया जाता है, और लेनदेन के समय को महीने के अनुसार समूहीकृत किया जाता है। थोड़ी देर बाद हम समूहीकरण (पदानुक्रम) के स्तरों पर अधिक विस्तार से विचार करेंगे।

चावल। 2. घन उदाहरण
क्यूब को "काटना"
यहां तक कि एक त्रि-आयामी घन को कंप्यूटर स्क्रीन पर प्रदर्शित करना मुश्किल होता है ताकि ब्याज के उपायों के मूल्यों को देखा जा सके। हम तीन से अधिक आयामों वाले घनों के बारे में क्या कह सकते हैं? क्यूब में संग्रहीत डेटा की कल्पना करने के लिए, एक नियम के रूप में, सामान्य द्वि-आयामी, यानी, सारणीबद्ध, विचारों का उपयोग किया जाता है, जिसमें जटिल पदानुक्रमित पंक्ति और कॉलम हेडर होते हैं।
एक घन का द्वि-आयामी प्रतिनिधित्व एक या अधिक अक्षों (आयामों) में "काट" कर प्राप्त किया जा सकता है: हम दो को छोड़कर सभी आयामों के मूल्यों को ठीक करते हैं, और हमें एक नियमित द्वि-आयामी तालिका मिलती है . तालिका का क्षैतिज अक्ष (कॉलम हेडर) एक आयाम का प्रतिनिधित्व करता है, ऊर्ध्वाधर अक्ष (पंक्ति शीर्षलेख) दूसरे आयाम का प्रतिनिधित्व करता है, और तालिका कक्ष माप मानों का प्रतिनिधित्व करते हैं। इस मामले में, उपायों के सेट को वास्तव में आयामों में से एक माना जाता है - हम या तो प्रदर्शन के लिए एक माप का चयन करते हैं (और फिर हम पंक्तियों और स्तंभों के शीर्षकों में दो आयाम रख सकते हैं), या हम कई उपाय दिखाते हैं (और फिर एक तालिका के कुल्हाड़ियों के उपायों के नाम पर कब्जा कर लिया जाएगा, और दूसरा - एक "अनकटा" आयाम का मान)।
अंजीर पर एक नजर डालें। 3 - यहाँ एक माप के लिए घन का द्वि-आयामी टुकड़ा है - यूनिट बिक्री (बेचे गए टुकड़े) और दो "अनकट" आयाम - स्टोर (स्टोर) और समय (समय)।

चावल। 3. एक माप के लिए द्वि-आयामी घन टुकड़ा
अंजीर पर। 4 केवल एक "बिना कटा हुआ" आयाम दिखाता है - स्टोर, लेकिन यह कई उपायों के मूल्यों को प्रदर्शित करता है - यूनिट बिक्री (बेचे गए टुकड़े), स्टोर बिक्री (बिक्री राशि) और स्टोर लागत (स्टोर व्यय)।

चावल। 4. कई उपायों के लिए 2डी क्यूब स्लाइसिंग
एक घन का द्वि-आयामी प्रतिनिधित्व तब भी संभव है जब दो से अधिक आयाम "अनकट" रहते हैं। इस मामले में, "कट" क्यूब के दो या अधिक आयामों को स्लाइस अक्षों (पंक्तियों और स्तंभों) पर रखा जाएगा - अंजीर देखें। 5.

चावल। 5. एक ही धुरी पर कई आयामों वाले घन का द्वि-आयामी टुकड़ा
टैग
आयामों के साथ "अलग सेट" मान सदस्यों या लेबल (सदस्य) कहलाते हैं। लेबल का उपयोग घन को "काटने" और चयनित डेटा को प्रतिबंधित (फ़िल्टर) करने के लिए किया जाता है - जब एक आयाम में जो "अनकट" रहता है, हम सभी मूल्यों में रुचि नहीं रखते हैं, लेकिन उनके सबसेट में, उदाहरण के लिए, कई में से तीन शहर दर्जन। लेबल मान 2D घन दृश्य में पंक्ति और स्तंभ शीर्षकों के रूप में दिखाई देते हैं।
पदानुक्रम और स्तर
लेबल को एक या अधिक स्तरों वाले पदानुक्रमों में संयोजित किया जा सकता है। उदाहरण के लिए, आयाम "स्टोर" (स्टोर) के लेबल स्वाभाविक रूप से स्तरों के साथ पदानुक्रम में संयुक्त होते हैं:
देश (देश)
राज्य (राज्य)
शहर (शहर)
स्टोर शॉप)।
पदानुक्रम के स्तरों के अनुसार, कुल मूल्यों की गणना की जाती है, जैसे संयुक्त राज्य अमेरिका ("देश" स्तर) या कैलिफ़ोर्निया ("राज्य" स्तर) के लिए बिक्री। एक आयाम में एक से अधिक पदानुक्रम लागू किए जा सकते हैं - समय के लिए कहें: (वर्ष, तिमाही, महीना, दिन) और (वर्ष, सप्ताह, दिन)।
ओएलएपी एप्लीकेशन आर्किटेक्चर
OLAP के बारे में जो कुछ ऊपर कहा गया है, वास्तव में, डेटा की बहुआयामी प्रस्तुति को संदर्भित करता है। जिस तरह से डेटा संग्रहीत किया जाता है, मोटे तौर पर बोलना, अंतिम उपयोगकर्ता या क्लाइंट द्वारा उपयोग किए जाने वाले टूल के डेवलपर्स से संबंधित नहीं है।
OLAP अनुप्रयोगों में बहुआयामीता को तीन स्तरों में विभाजित किया जा सकता है:
- बहुआयामी डेटा प्रतिनिधित्व - अंत-उपयोगकर्ता उपकरण जो बहुआयामी दृश्य और डेटा हेरफेर प्रदान करते हैं; बहुआयामी प्रतिनिधित्व परत डेटा की भौतिक संरचना से सार करती है और डेटा को बहुआयामी मानती है।
- बहुआयामी प्रसंस्करण - बहुआयामी प्रश्नों को तैयार करने के लिए एक उपकरण (भाषा) (पारंपरिक संबंधपरक SQL भाषा यहाँ अनुपयुक्त है) और एक प्रोसेसर जो इस तरह की क्वेरी को संसाधित और निष्पादित कर सकता है।
- बहुआयामी भंडारण - डेटा के भौतिक संगठन का मतलब है जो बहुआयामी प्रश्नों का कुशल निष्पादन प्रदान करता है।
सभी OLAP टूल में पहले दो स्तर अनिवार्य हैं। तीसरा स्तर, हालांकि व्यापक रूप से उपयोग किया जाता है, इसकी आवश्यकता नहीं है, क्योंकि बहुआयामी प्रतिनिधित्व के लिए डेटा को साधारण संबंधपरक संरचनाओं से भी पुनर्प्राप्त किया जा सकता है; इस मामले में बहुआयामी क्वेरी प्रोसेसर बहुआयामी प्रश्नों को एसक्यूएल प्रश्नों में अनुवादित करता है जो एक रिलेशनल डीबीएमएस द्वारा निष्पादित होते हैं।
विशिष्ट OLAP उत्पाद आमतौर पर या तो एक बहुआयामी डेटा प्रस्तुति उपकरण होते हैं, एक OLAP क्लाइंट (उदाहरण के लिए, Microsoft से Excel 2000 में पिवट टेबल या नोसिस से ProClarity), या एक बहुआयामी बैक-एंड DBMS, एक OLAP सर्वर (उदाहरण के लिए, Oracle एक्सप्रेस सर्वर) या Microsoft OLAP सेवाएँ)।
बहुआयामी प्रसंस्करण परत आमतौर पर OLAP क्लाइंट और/या OLAP सर्वर में निर्मित होती है, लेकिन इसे इसके शुद्धतम रूप में अलग किया जा सकता है, जैसे कि Microsoft की पिवट टेबल सर्विस घटक।
बहुआयामी डेटा भंडारण के तकनीकी पहलू
जैसा कि ऊपर उल्लेख किया गया है, OLAP विश्लेषण उपकरण रिलेशनल सिस्टम से सीधे डेटा भी निकाल सकते हैं। यह दृष्टिकोण उस समय अधिक आकर्षक था जब OLAP सर्वर प्रमुख डेटाबेस विक्रेताओं की मूल्य सूची में नहीं थे। लेकिन आज, Oracle, Informix और Microsoft पूर्ण विकसित OLAP सर्वर प्रदान करते हैं, और यहां तक कि वे IT प्रबंधक जो अपने नेटवर्क में विभिन्न निर्माताओं के सॉफ़्टवेयर का "चिड़ियाघर" लगाना पसंद नहीं करते हैं, खरीद सकते हैं (अधिक सटीक रूप से, संबंधित अनुरोध के साथ आवेदन करें) कंपनी के प्रबंधन के लिए) मुख्य डेटाबेस सर्वर के समान ब्रांड का OLAP सर्वर।
OLAP सर्वर, या बहुआयामी डेटाबेस सर्वर, अपने बहुआयामी डेटा को विभिन्न तरीकों से स्टोर कर सकते हैं। इन विधियों पर विचार करने से पहले, हमें समुच्चय के भंडारण जैसे एक महत्वपूर्ण पहलू के बारे में बात करने की आवश्यकता है। तथ्य यह है कि किसी भी डेटा वेयरहाउस में - एक नियमित और बहुआयामी दोनों में - परिचालन प्रणालियों से प्राप्त विस्तृत डेटा के साथ, सारांश संकेतक (एकत्रित संकेतक, समुच्चय) भी संग्रहीत किए जाते हैं, जैसे कि महीनों में बिक्री की मात्रा, श्रेणियों द्वारा माल, आदि। कुल मिलाकर क्वेरी निष्पादन को गति देने के एकमात्र उद्देश्य के लिए स्पष्ट रूप से संग्रहीत किया जाता है। आखिरकार, एक ओर, एक नियम के रूप में, भंडारण में बहुत बड़ी मात्रा में डेटा जमा होता है, और दूसरी ओर, विश्लेषक ज्यादातर मामलों में विस्तृत नहीं, बल्कि सामान्यीकृत संकेतकों में रुचि रखते हैं। और यदि वर्ष के लिए बिक्री की मात्रा की गणना करने के लिए हर बार लाखों व्यक्तिगत बिक्री को जोड़ना पड़ता है, तो गति सबसे अधिक अस्वीकार्य होगी। इसलिए, डेटा को एक बहुआयामी डेटाबेस में लोड करते समय, सभी कुल संकेतक या उनके हिस्से की गणना की जाती है और सहेजी जाती है।
लेकिन, जैसा कि आप जानते हैं, आपको हर चीज के लिए भुगतान करना होगा। और आपको डेटा की मात्रा और उन्हें लोड करने में लगने वाले समय को बढ़ाकर सारांश डेटा के प्रसंस्करण प्रश्नों की गति के लिए भुगतान करना होगा। इसके अलावा, मात्रा में वृद्धि शाब्दिक रूप से विनाशकारी हो सकती है - प्रकाशित मानक परीक्षणों में से एक में, प्रारंभिक डेटा के 10 एमबी के लिए समुच्चय की पूरी गणना के लिए 2.4 जीबी की आवश्यकता होती है, अर्थात, डेटा 240 गुना बढ़ गया! समुच्चय की गणना करते समय डेटा "सूजन" की डिग्री घन आयामों की संख्या और इन आयामों की संरचना पर निर्भर करती है, अर्थात आयाम के विभिन्न स्तरों पर "पिता" और "बच्चों" की संख्या का अनुपात। समेकन के भंडारण की समस्या को हल करने के लिए कभी-कभी उपयोग किया जाता है जटिल योजनाएँ, जो क्वेरी निष्पादन के प्रदर्शन में महत्वपूर्ण वृद्धि प्राप्त करने के लिए, सभी संभावित समुच्चय से बहुत दूर की गणना करते समय अनुमति देते हैं।
अब जानकारी संग्रहीत करने के विभिन्न विकल्पों के बारे में। विस्तृत डेटा और समुच्चय दोनों को संबंधपरक या बहुआयामी संरचनाओं में संग्रहीत किया जा सकता है। बहुआयामी भंडारण आपको डेटा को बहुआयामी सरणी के रूप में व्यवहार करने की अनुमति देता है, जो किसी भी आयाम पर योग और विभिन्न बहुआयामी परिवर्तनों की समान तेज़ गणना प्रदान करता है। कुछ समय पहले, OLAP उत्पादों ने संबंधपरक या बहुआयामी भंडारण का समर्थन किया था। आज, एक नियम के रूप में, एक ही उत्पाद इन दोनों प्रकार के भंडारण के साथ-साथ तीसरे प्रकार - मिश्रित प्रदान करता है। निम्नलिखित शर्तें लागू होती हैं:
- मोलाप(बहुआयामी OLAP) - विस्तृत डेटा और समुच्चय दोनों को एक बहुआयामी डेटाबेस में संग्रहीत किया जाता है। इस मामले में, सबसे बड़ा अतिरेक प्राप्त होता है, क्योंकि बहुआयामी डेटा में पूरी तरह से संबंधपरक डेटा होता है।
- रोलप(रिलेशनल OLAP) - विस्तृत डेटा वहीं रहता है जहाँ वे मूल रूप से "रहते थे" - एक रिलेशनल डेटाबेस में; समुच्चय एक ही डेटाबेस में विशेष रूप से निर्मित सेवा तालिकाओं में संग्रहीत किए जाते हैं।
- होलाप(हाइब्रिड OLAP) - विस्तृत डेटा जगह में रहता है (रिलेशनल डेटाबेस में), जबकि समुच्चय एक बहुआयामी डेटाबेस में संग्रहीत होते हैं।
इन विधियों में से प्रत्येक के अपने फायदे और नुकसान हैं और इनका उपयोग शर्तों के आधार पर किया जाना चाहिए - डेटा की मात्रा, रिलेशनल DBMS की शक्ति, आदि।
बहुआयामी संरचनाओं में डेटा संग्रहीत करते समय, खाली मूल्यों के भंडारण के कारण "ब्लोट" की संभावित समस्या होती है। आखिरकार, यदि माप लेबल के सभी संभावित संयोजनों के लिए एक बहुआयामी सरणी में एक स्थान आरक्षित है, और वास्तव में केवल एक छोटा सा हिस्सा भरा जाता है (उदाहरण के लिए, कई उत्पाद केवल कुछ ही क्षेत्रों में बेचे जाते हैं), तो अधिकांश घन खाली होगा, हालांकि जगह भर जाएगी। आधुनिक OLAP उत्पाद इस समस्या से निपटने में सक्षम हैं।
करने के लिए जारी। भविष्य में, हम अग्रणी निर्माताओं द्वारा निर्मित विशिष्ट OLAP उत्पादों के बारे में बात करेंगे।
OLAP कोई एक सॉफ्टवेयर उत्पाद नहीं है, कोई प्रोग्रामिंग भाषा नहीं है, और एक विशिष्ट तकनीक भी नहीं है। यदि आप OLAP को उसकी सभी अभिव्यक्तियों में शामिल करने का प्रयास करते हैं, तो यह अवधारणाओं, सिद्धांतों और आवश्यकताओं का एक समूह है जो सॉफ़्टवेयर उत्पादों के अंतर्गत आता है जो विश्लेषकों के लिए डेटा तक पहुँच को आसान बनाता है। चलो पता करते हैं किसलिएविश्लेषकों को कुछ खास चाहिए आसान करनाडेटा प्राप्त करना।
तथ्य यह है कि विश्लेषक कॉर्पोरेट जानकारी के विशेष उपभोक्ता हैं। एक विश्लेषक का काम बड़े डेटा सरणियों में पैटर्न खोजना है. इसलिए, विश्लेषक इस तथ्य पर ध्यान नहीं देंगे कि गुरुवार को चौथे दिन प्रतिपक्ष चेर्नोव को काली स्याही का एक बैच बेचा गया था - उन्हें जानकारी चाहिए लगभग सैकड़ों और हजारोंसमान घटनाएँ। डेटाबेस में एकल तथ्य रुचि के हो सकते हैं, उदाहरण के लिए, लेखाकार या बिक्री विभाग के प्रमुख, जिनकी क्षमता में लेनदेन स्थित है। एक विश्लेषक के लिए एक रिकॉर्ड पर्याप्त नहीं है - उदाहरण के लिए, उसे एक महीने या एक वर्ष के लिए किसी शाखा या प्रतिनिधि कार्यालय के सभी लेन-देन की आवश्यकता हो सकती है। साथ ही विश्लेषक को छोड़ देता हैखरीदार का टीआईएन, उसका सटीक पता और फोन नंबर, अनुबंध सूचकांक और इसी तरह के अनावश्यक विवरण। उसी समय, जिस डेटा को एक विश्लेषक को काम करने की आवश्यकता होती है, उसमें आवश्यक रूप से संख्यात्मक मान होते हैं - यह उसकी गतिविधि के बहुत सार के कारण होता है।
इसलिए, एक विश्लेषक को बहुत अधिक डेटा की आवश्यकता होती है, यह डेटा चयनात्मक होता है और इसकी प्रकृति भी होती है " विशेषता सेट - संख्या"। बाद का मतलब है कि विश्लेषक निम्न प्रकार की तालिकाओं के साथ काम करता है:
यहाँ " एक देश", "उत्पाद", "वर्ष"गुण हैं या मापन, ए " बिक्री की मात्रा" - इस प्रकार एक संख्यात्मक मान या उपाय. हम दोहराते हैं कि विश्लेषक का कार्य विशेषताओं और संख्यात्मक मापदंडों के बीच लगातार संबंधों की पहचान करना है।. तालिका को देखते हुए, आप देख सकते हैं कि इसे आसानी से तीन आयामों में अनुवादित किया जा सकता है: एक कुल्हाड़ियों पर हम देशों को रखते हैं, दूसरे पर - माल, तीसरे - वर्षों पर। और इस त्रि-आयामी सरणी में मान संबंधित बिक्री वॉल्यूम होंगे।

तालिका का 3D प्रतिनिधित्व। ग्रे खंड दर्शाता है कि 1988 में अर्जेंटीना के लिए कोई डेटा नहीं है
यह OLAP के संदर्भ में ऐसी त्रि-आयामी सरणी है जिसे क्यूब कहा जाता है। वास्तव में, सख्त गणित के दृष्टिकोण से, ऐसी सरणी हमेशा एक घन नहीं होगी: एक वास्तविक घन के लिए, सभी आयामों में तत्वों की संख्या समान होनी चाहिए, जबकि OLAP घनों में ऐसी कोई सीमा नहीं होती है। हालांकि, इन विवरणों के बावजूद, "OLAP क्यूब्स" शब्द, इसकी संक्षिप्तता और कल्पना के कारण, आम तौर पर स्वीकृत हो गया है। एक OLAP क्यूब का 3D होना बिल्कुल भी आवश्यक नहीं है। हल की जा रही समस्या के आधार पर यह द्वि-आयामी और बहुआयामी दोनों हो सकता है। विशेष रूप से अनुभवी विश्लेषकों को लगभग 20 मापों की आवश्यकता हो सकती है - और गंभीर OLAP उत्पादों को केवल इतनी ही संख्या के लिए डिज़ाइन किया गया है। अधिक सरल डेस्कटॉप एप्लिकेशन लगभग 6 आयामों का समर्थन करते हैं।
मापन OLAP क्यूब्स तथाकथित से बने होते हैं निशानया सदस्य। उदाहरण के लिए, आयाम "देश" में "अर्जेंटीना", "ब्राज़ील", "वेनेज़ुएला", और इसी तरह के लेबल शामिल हैं।
क्यूब के सभी तत्वों को नहीं भरा जाना चाहिए: यदि अर्जेंटीना में 1988 में रबर उत्पादों की बिक्री के बारे में कोई जानकारी नहीं है, तो संबंधित सेल में मूल्य निर्धारित नहीं किया जाएगा। यह भी आवश्यक नहीं है कि एक OLAP एप्लिकेशन आवश्यक रूप से बहुआयामी संरचना में डेटा संग्रहीत करता है - मुख्य बात यह है कि उपयोगकर्ता के लिए यह डेटा बिल्कुल वैसा ही दिखता है। वैसे, यह बहुआयामी डेटा के कॉम्पैक्ट स्टोरेज के विशेष तरीकों में ठीक है कि क्यूब्स में "वैक्यूम" (अनफिल्ड एलिमेंट्स) मेमोरी की बर्बादी का कारण नहीं बनता है।
हालाँकि, घन स्वयं विश्लेषण के लिए उपयुक्त नहीं है। यदि अभी भी त्रि-आयामी घन का पर्याप्त रूप से प्रतिनिधित्व या चित्रण करना संभव है, तो छह या उन्नीस आयामों के साथ स्थिति बहुत खराब है। इसीलिए इस्तेमाल से पहलेसाधारण घन एक बहुआयामी घन से निकाले जाते हैं द्वि-आयामी टेबल. इस ऑपरेशन को क्यूब को "कटिंग" कहा जाता है। फिर से, यह शब्द आलंकारिक है। विश्लेषक, जैसा कि वह था, घन के आयामों को उसके लिए ब्याज के निशान के अनुसार लेता है और "कट" करता है। इस तरह, विश्लेषक घन का द्वि-आयामी टुकड़ा प्राप्त करता है और इसके साथ काम करता है। लगभग उसी तरह, लंबरजैक एक आरी कट पर वार्षिक रिंगों की गिनती करते हैं।
तदनुसार, एक नियम के रूप में, केवल दो आयाम "अनकट" रहते हैं - तालिका के आयामों की संख्या के अनुसार। ऐसा होता है कि केवल आयाम "अनकट" रहता है - यदि घन में कई प्रकार के संख्यात्मक मान होते हैं, तो उन्हें तालिका के आयामों में से एक के अनुसार प्लॉट किया जा सकता है।
यदि आप उस तालिका पर करीब से नज़र डालते हैं जिसे हमने पहले चित्रित किया था, तो आप देख सकते हैं कि इसमें डेटा, सबसे अधिक संभावना है, प्राथमिक नहीं हैं, लेकिन परिणाम के रूप में प्राप्त किए गए हैं योगछोटी वस्तुओं के लिए। उदाहरण के लिए, एक वर्ष को तिमाहियों में, तिमाहियों को महीनों में, महीनों को सप्ताहों में, सप्ताहों को दिनों में विभाजित किया जाता है। एक देश क्षेत्रों से बना है, और क्षेत्र इलाकों से बने हैं। अंत में, शहरों में ही, जिलों और विशिष्ट खुदरा दुकानों को प्रतिष्ठित किया जा सकता है। उत्पादों को उत्पाद समूहों आदि में जोड़ा जा सकता है। OLAP के संदर्भ में, ऐसे मल्टीलेवल जॉइन को तार्किक रूप से कहा जाता है पदानुक्रम. OLAP उपकरण किसी भी समय पदानुक्रम के वांछित स्तर तक ले जाना संभव बनाते हैं। इसके अलावा, एक नियम के रूप में, समान तत्वों के लिए कई प्रकार के पदानुक्रम समर्थित हैं: उदाहरण के लिए, दिन-सप्ताह-महीने या दिन-दशक-तिमाही। स्रोत डेटा को पदानुक्रम के निचले स्तरों से लिया जाता है और फिर उच्च स्तरों के मूल्यों को प्राप्त करने के लिए संक्षेप में प्रस्तुत किया जाता है। संक्रमण प्रक्रिया को गति देने के लिए, विभिन्न स्तरों के योग किए गए मानों को घन में संग्रहीत किया जाता है। इस प्रकार, जो उपयोगकर्ता की ओर से एक घन जैसा दिखता है, मोटे तौर पर बोल रहा है, इसमें कई और आदिम घन शामिल हैं।

पदानुक्रम उदाहरण
यह उन आवश्यक बिंदुओं में से एक है जिसके कारण OLAP - उत्पादकता और दक्षता का उदय हुआ। आइए कल्पना करें कि क्या होता है जब एक विश्लेषक को जानकारी प्राप्त करने की आवश्यकता होती है, और उद्यम में OLAP उपकरण उपलब्ध नहीं होते हैं। विश्लेषक स्वतंत्र रूप से (जिसकी संभावना नहीं है) या एक प्रोग्रामर की मदद से एक उपयुक्त SQL क्वेरी बनाता है और एक रिपोर्ट के रूप में ब्याज का डेटा प्राप्त करता है या इसे एक स्प्रेडशीट में निर्यात करता है। इससे काफी दिक्कतें होती हैं। सबसे पहले, विश्लेषक को अपनी नौकरी (एसक्यूएल प्रोग्रामिंग) के अलावा कुछ और करने के लिए मजबूर होना पड़ता है या प्रोग्रामर को उसके लिए कार्य करने की प्रतीक्षा करनी पड़ती है - यह सब श्रम उत्पादकता, हमले, दिल का दौरा और स्ट्रोक स्तर में वृद्धि को नकारात्मक रूप से प्रभावित करता है, और इसी तरह . दूसरे, एक एकल रिपोर्ट या तालिका, एक नियम के रूप में, विचार के दिग्गजों और रूसी विश्लेषण के पिता को नहीं बचाती है - और पूरी प्रक्रिया को बार-बार दोहराना होगा। तीसरा, जैसा कि हम पहले ही पता लगा चुके हैं, विश्लेषक ट्रिफ़ल्स नहीं माँगते - उन्हें एक ही बार में सब कुछ चाहिए। इसका मतलब है (हालांकि तकनीक छलांग और सीमा से आगे बढ़ रही है) कि विश्लेषक द्वारा एक्सेस किए गए एंटरप्राइज रिलेशनल डेटाबेस सर्वर बाकी लेनदेन को अवरुद्ध करते हुए गहराई से और लंबे समय तक सोच सकते हैं।
ऐसी समस्याओं को हल करने के लिए OLAP की अवधारणा ठीक दिखाई दी। OLAP क्यूब्स अनिवार्य रूप से मेटा-रिपोर्ट हैं। आयामों द्वारा मेटा-रिपोर्ट (क्यूब्स, यानी) को काटकर, विश्लेषक वास्तव में उसके लिए ब्याज की "नियमित" द्वि-आयामी रिपोर्ट प्राप्त करता है (ये आवश्यक रूप से शब्द के सामान्य अर्थों में रिपोर्ट नहीं हैं - हम डेटा संरचनाओं के बारे में बात कर रहे हैं समान कार्यों के साथ)। क्यूब्स के फायदे स्पष्ट हैं - क्यूब बनाते समय डेटा को रिलेशनल डीबीएमएस से केवल एक बार अनुरोध करने की आवश्यकता होती है। चूंकि विश्लेषक, एक नियम के रूप में, उस जानकारी के साथ काम नहीं करते हैं जो पूरक है और मक्खी पर बदल जाती है, उत्पन्न क्यूब काफी लंबे समय तक प्रासंगिक रहता है। इसके लिए धन्यवाद, रिलेशनल DBMS सर्वर के संचालन में रुकावटें न केवल समाप्त हो जाती हैं (हजारों और लाखों प्रतिक्रिया लाइनों के साथ कोई प्रश्न नहीं हैं), बल्कि स्वयं विश्लेषक के लिए डेटा एक्सेस गति भी नाटकीय रूप से बढ़ जाती है। इसके अलावा, जैसा कि पहले ही उल्लेख किया गया है, घन निर्माण के समय पदानुक्रमों और अन्य एकत्रित मूल्यों के सबसम की गणना करके प्रदर्शन में भी सुधार किया जाता है। यही है, अगर शुरू में हमारे डेटा में एक स्टोर में किसी विशिष्ट उत्पाद के लिए दैनिक राजस्व के बारे में जानकारी थी, तो क्यूब बनाते समय, OLAP एप्लिकेशन विभिन्न स्तरों के पदानुक्रम (सप्ताह और महीने, शहर और देश) के लिए योग की गणना करता है।
बेशक, आपको इस तरह से उत्पादकता बढ़ाने के लिए भुगतान करना होगा। कभी-कभी यह कहा जाता है कि एक डेटा संरचना बस "विस्फोट" करती है - ओलाप क्यूबमूल डेटा की तुलना में दसियों या सैकड़ों गुना अधिक स्थान ले सकता है।
प्रश्नों के उत्तर दें:
क्या हुआ है घनक्षेत्र ओलाप?
क्या हुआ है लेबल विशिष्ट आयाम? उदाहरण दो।
क्या वे कर सकते हैं पैमाने एक OLAP घन में, गैर-संख्यात्मक मान होते हैं।